CS
🚴🏽 언어별 동시성 프로그래밍
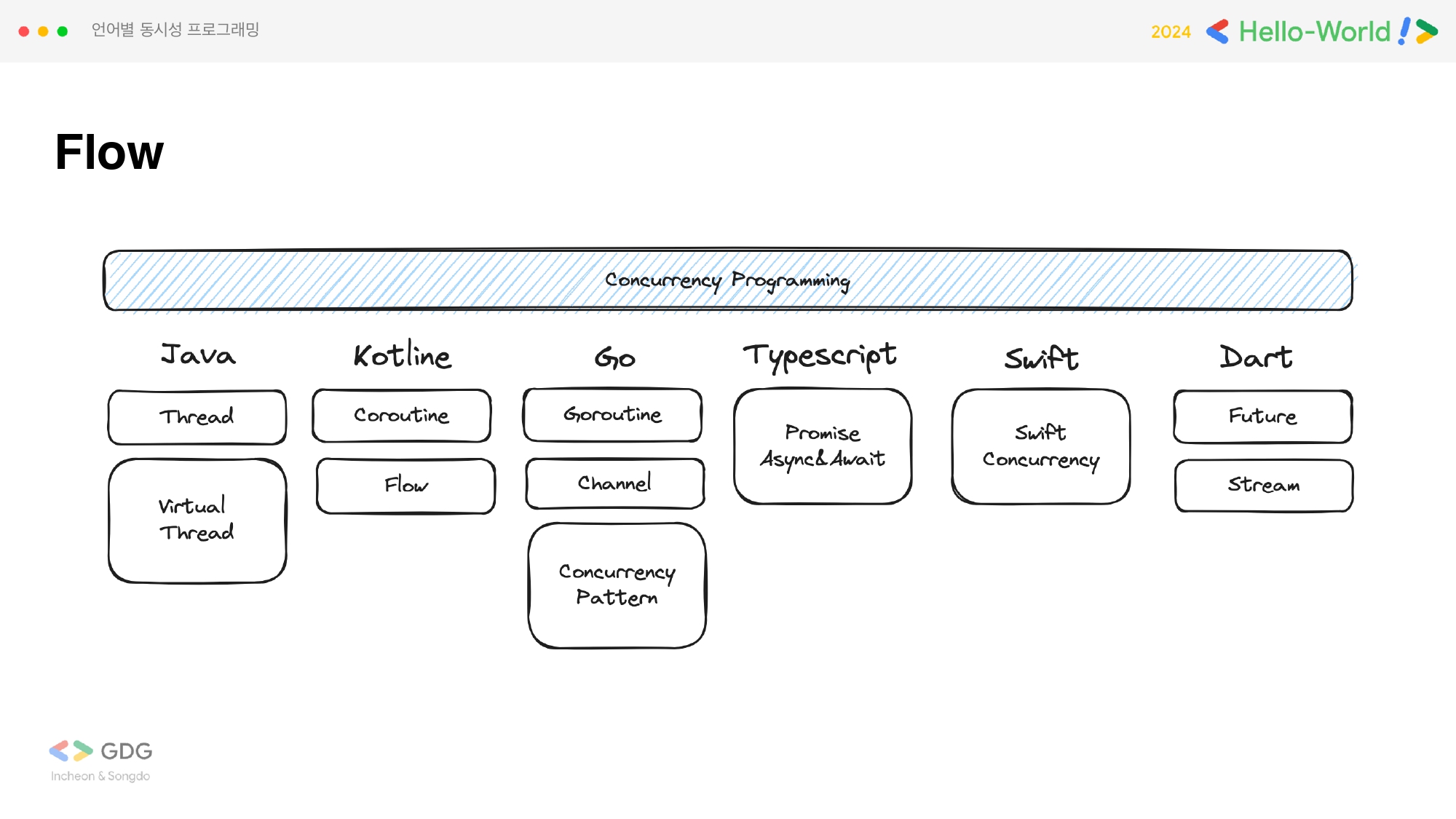
Contents
- 들어가며
- Java와 동시성 프로그래밍
- Kotlin와 동시성 프로그래밍
- Go와 동시성 프로그래밍
- Typescript와 동시성 프로그래밍
- Swift와 동시성 프로그래밍
- Dart와 동시성 프로그래밍
- 발표 내용을 정리하면서
들어가며
저는 이번 2024년 Hello World 발표 주제로 언어별 동시성 프로그래밍을 선정했었습니다! 3월 30일이었으니까 벌써 1달이 지났네요.
난이도가 정말 어려운 주제였지만 제게 필요하고 저와 같은 다른 주니어들에게 필요하고 한 번쯤 생각해 볼 만한 주제!라고 생각해서 발표주제로 선정했습니다. 발표를 준비하면서 많은 분들의 도움을 얻었고 저 역시 깊게 생각해보는 좋은 기회가 되지 않았을까 생각합니다. 그리고 발표 내용을 정리하면서 복기하기 위해 블로그에 일부 내용을 정리하게 되었습니다.
먼저 동시성 프로그래밍하면 나오는 단어들을 정리해봤습니다.
동시성이란 병행적 개념으로 실제로 한 번에 일이 처리되는 것 같지만, 단일코어의 컨텍스트 스위칭과 같이 여러 작업이 진행되는 것을 의미합니다. 반면, 병렬성이란 물리적으로 작업들이 분리되어 실행되는 것을 의미하는데 멀티코어, 멀티 프로세서 같은 구조로 병렬성이 가능합니다. 동시성 프로그램밍에서 동시성과 병렬은 보완적 개념으로 함께 사용되어 성능과 효율성을 높이기 위해 함께 사용됩니다.
멀티프로세스와 멀티스레드는 말그대로 프로세스가 여러 개, 스레드가 여러 개인 개념입니다. 프로세스가 메모리 할당을 필요로 하기 때문에 멀티 프로세스는 리소스 사용량이 높다는 단점이 있습니다. 반대로 멀티스레드는 한 프로세스 내에서 여러 스레드를 두고 빠른 작업을 처리할 수 있게 합니다. 한 프로세스 내에서 동작하기 때문에 동기화 문제가 발생할 수 있다는 단점이 있습니다.
프로세스 흐름 제어 방식으로는 동기와 비동기가 있습니다. 동기는 작업이 모두 완료되면 다른 작업을 순차적으로 실행한다면, 비동기는 블로킹 작업이여도 다른 작업을 실행하고 다른 작업과의 의존성을 줄일 수 있게 됩니다.
Java와 동시성 프로그래밍
Java는 Runnable 인터페이스로 구현하며, 오버라이드된 run 메서드로 스레드에서 실행될 내용을 구현합니다. 메서드나 코드 블록의 동기화는 synchronized로 지원하는데, 감소 연산자(예로 들면, availableTickets–;)와 같은 부분을 하나의 원자성 작업으로 실행될 수 있도록 해줍니다.
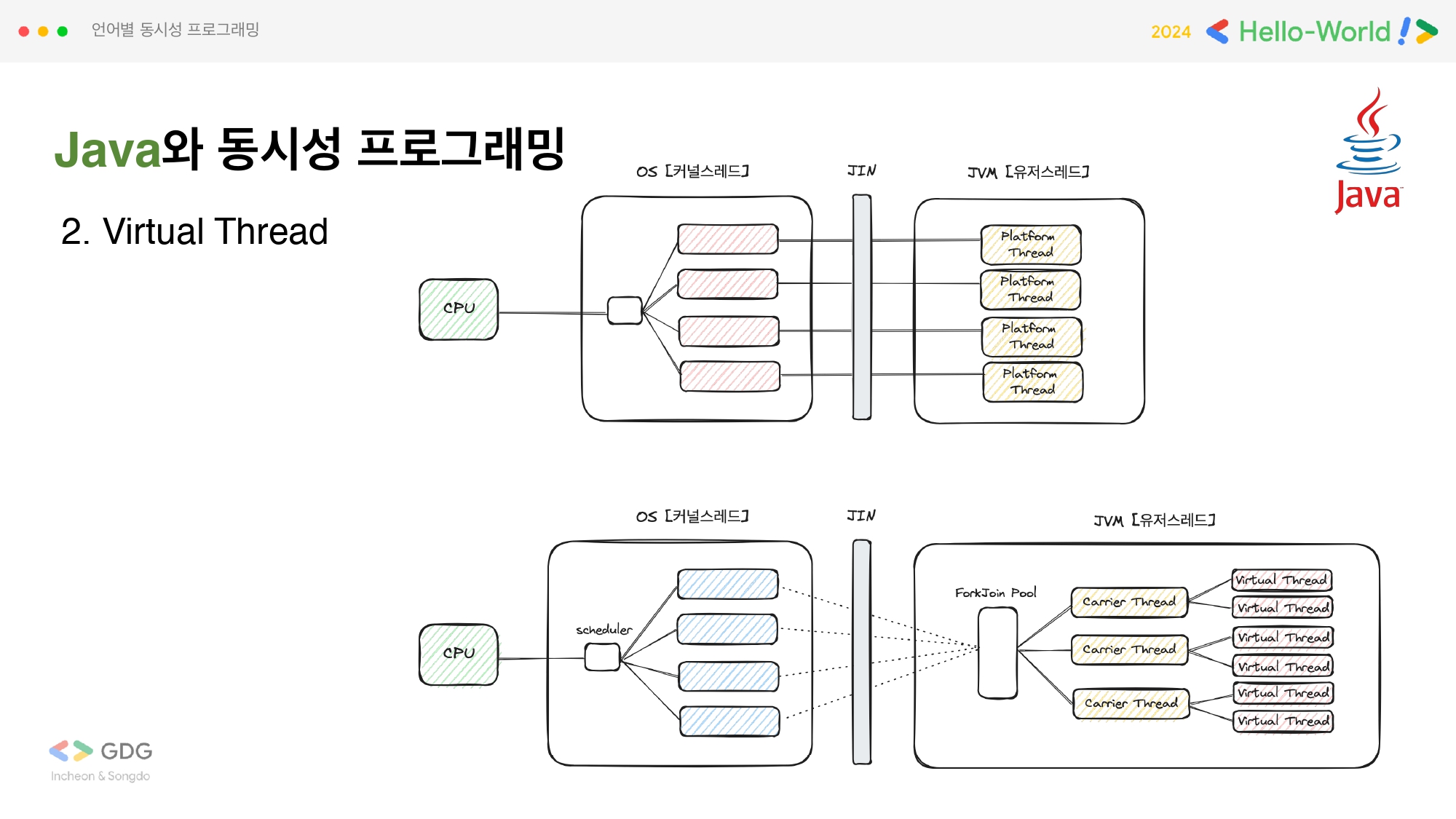
Virtual Thread
preview 19, 21 버전부터 Java는 Virtual Thread를 제공하는데 아마 다른 언어들에서 적용된 경량 스레드 개념을 제공해야하지 않나 하는 즉, 기존의 1:1 매핑의 JVM 스레드 개념을 개선하기 위한 취지로 나온 것입니다. 경량화된 user-mode 스레드 개념을 도입하므로서 OS 스레드와 직접적으로 연결되지 않고 Carrier Thread에 연결해 컨텍스트 스위칭 비용과 Blocking 타임을 낮추는 것을 말합니다. Virtual Thread는 Executor와 Thread 클래스 빌더 개념을 사용해서 만들 수 있습니다.
synchronized, native 메서드를 사용하는 경우에 대해 Carrier Thread에 pin되어 성능이 저하되는 경우가 발생합니다. 따라서 특정 플랫폼 스레드에 고정시켜 JVM의 자유로운 스레드 관리를 방해하게 되는 문제가 생깁니다. Spring에서는 동기화 처리에 대해 synchronized를 사용하는 부분들을 점차 ReentrantLock을 사용한 방식으로 전환하고 있습니다.
ReentrantLock 역시 Java에서 지원하고 있던 개념이지만, 명시적으로 락의 시점을 제어하기 때문에 JVM 내부적으로 구현된 synchronized에 의한 Virtual Thread 활용에 대한 대응을 할 수 없다는 단점이 있습니다. - ReentrantReadWriteLock을 이용하면 read와 write락을 따로 구분해서 적용할 수 있는데, 읽기 작업의 병렬성을 가능하게 하기 때문에 블로킹 처리에 더 유연하게 대처할 수 있습니다.
Kotlin과 동시성 프로그래밍
Kotlin도 JVM에서 실행되기 때문에, Java의 Thread 클래스와 같은 기본적인 스레드 모델을 공유합니다. Java에는 없는 코틀린의 특별한 경량스레드 coroutine에 대해 알아보겠습니다. coroutine은 비동기 프로그래밍에 중요한 개념으로 어셈블리 프로그램부터 있던 개념입니다. 즉 단어 자체는 코틀린에서 생긴 개념은 아닙니다.
Corutine
먼저 구성을 살펴보면, 코루틴 스코프, 코루틴 콘텍스트, 코루틴으로 되어 있는 것을 볼 수 있습니다. 코루틴 스코프는 생명주기를 정의하고 메모리 누수를 관리합니다. 코루틴 콘텍스트는 코루틴의 생명주기를 관리하고 코루틴이 실행될 스레드를 결정합니다. 스코프, 콘텍스트, 코루틴 자체는 그림에서는 완전 분리된 것처럼 보일 수 있지만 각각 밀접한 관련이 되어 있습니다. 여기서 코루틴이 실제 실행에 필요한 코드를 담고 있다면, 컨텍스트의 Job은 코루틴의 상태 값을 가지고 있어 메타데이터를 담고 있는 개념으로 이해할 수 있습니다.
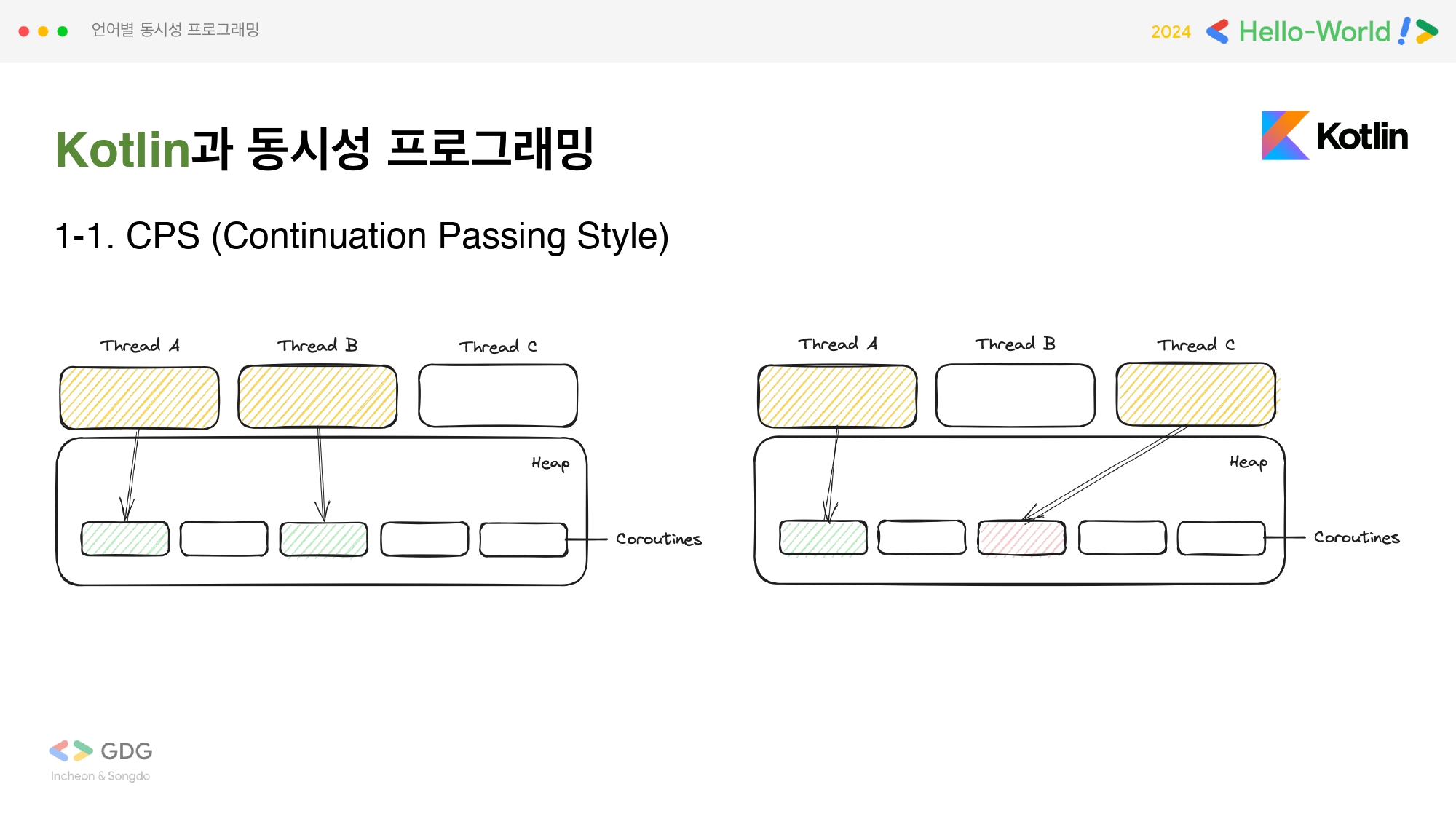
Continuation Passing Style
코루틴은 heap에 위치해서 하나의 스레드 안에서 별도의 context switching 없이 스케쥴링을 가능하게 합니다. 코루틴의 작업을 스레드가 할당받아서 처리를 하다가 중단되는 경우, 다른 스레드에 이어서 다시 작업을 진행할 수 있습니다. 이걸 가능하게 하는 것이 바로 CPS 패러다임으로 Continuation Passing Style이라고 합니다.
CPS 측면에 대해 코드로 살펴보겠습니다. 코틀린에서는 중단함수(suspend 함수)은 코루틴 내에서 비동기적 작업을 수행합니다. 이 때 이 중단함수를 디컴파일 하면, 코루틴 작업이 중단되었을 경우 이어서 작업 진행이 가능하도록 Continuation 객체와 State Machine이 생성됩니다. Continuation 객체는 State Machine과 함께 작동하여 중단 함수의 실행을 관리하고 완료된 후에는 결과를 반환합니다. State Machine은 중단 함수의 실행 흐름을 제어하고 중단된 상태를 유지합니다. 즉, State Machine을 사용하므로써 중단점 레이블에서 작업 실행을 재개할 수 있게 됩니다.
Structured Concurrency
코틀린의 Structured Concurrency는 흔히 말하는 부모-자식의 계층적 구조를 말하며, 그 계층 구조 내에서 일관된 패턴을 갖게 되는 것을 말합니다. 따라서 그 최상위 스코프가 취소되는 경우 그 안의 코루틴도 모두 함께 취소된다는 특징을 갖습니다.
Flow
Flow는 비동기 데이터 스트림을 다루기 위한 API로 코루틴은 아니지만, 코루틴과 함깨 사용되어 시간이 지남에 따라 구독자가 요청(collect)을 호출하멩 따라 데이터를 하나씩 생성, 방출하는 콜드 스트림입니다. return 값이 여러 개라는 점에서 suspend 함수와 차이가 있습니다. 주로 네트워크 호출이나 데이터베이스 쿼리와 같이 비동기적으로 발생하는 이벤트를 처리할 때 사용됩니다.
Go와 동시성 프로그래밍
Go라고 하면, 가장 먼저 Go스러움에 대해 설명할 수 있는데 안정적이고 가볍고 빠르고 동시성을 지원하는 언어적 특징을 가지고 있습니다.
안정적이라는 말은 타입 안정성을 지원해서 interface와 같은 빈 인터페이스를 사용하며, type assertion이나 reflect를 이용하는 것을 지양하는 것을 말합니다. Java를 사용하면서 간혹 프로젝트에서 reflection에 대한 안정성이 우려스러운 부분을 본 적이 있는데, 반면 Go는 타입 검사를 통해 안정성을 추구합니다.
그리고 Spring MVC와 같은 무거운 개발 방식보다는 간결하고 빠르게 개발을 할 수 있는 경량화된 프레임워크들을 사용합니다.
동시성에 대한 지원은 goroutine과 channel으로 이뤄지는데 이 포스팅에서는 이 부분에 대해 간략하게 살펴보겠습니다.
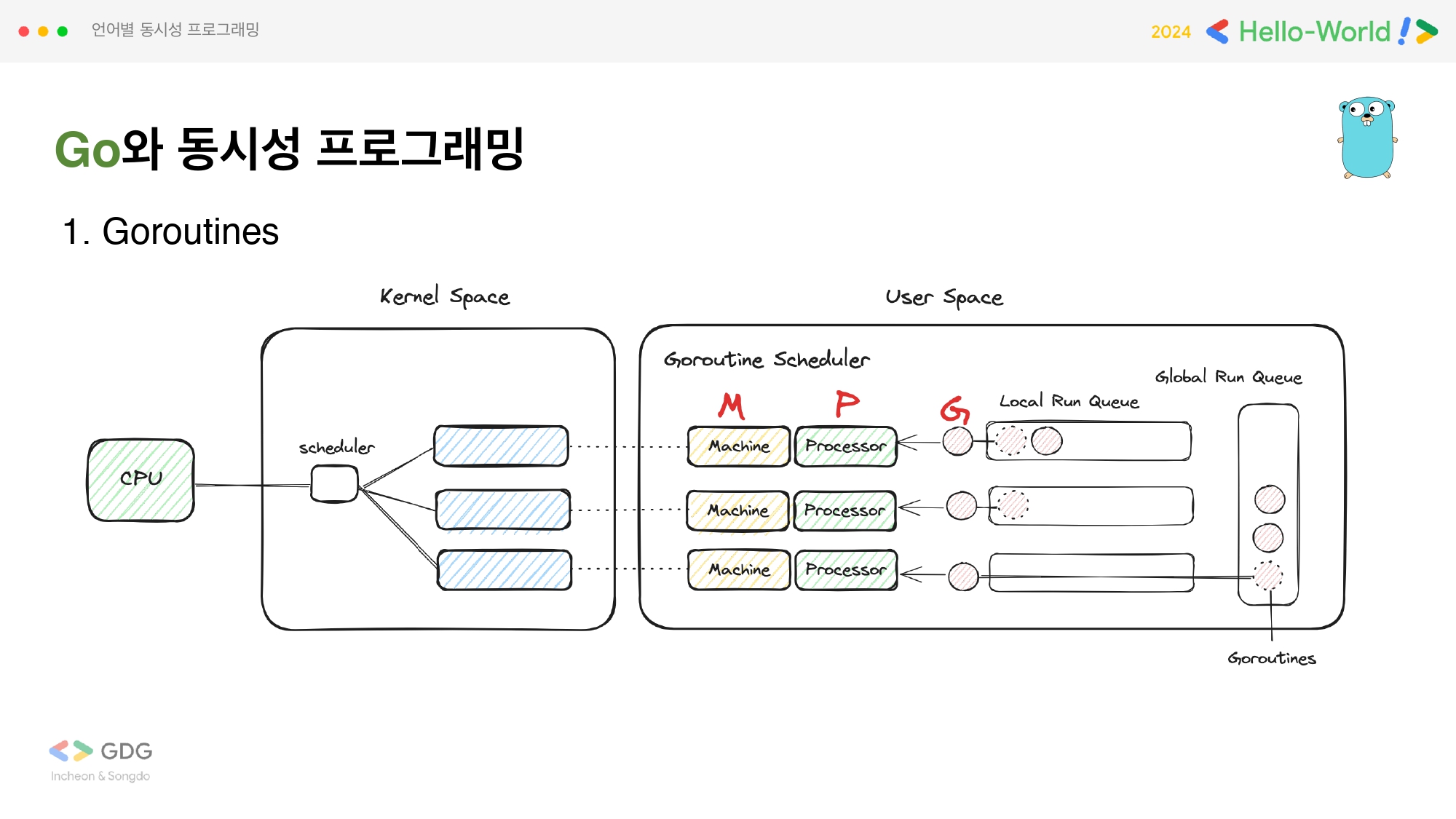
Gorutine
코틀린에 코루틴이 있다면 고 언어에는 고루틴이 있습니다. 이것도 앞서 살펴본 코루틴처럼 경량 스레드 개념입니다. 그래서 동일하게 그래서 비용이 OS에 의한 Process, Thread의 Context Switching에 비해 현저히 낮습니다.
GMP 모델은 Go에서 Go runtime이 thread를 관리하는 방법을 말합니다. 위의 이미지에서 각각 G, M, P 부분을 찾을 수 있습니다. 여기서 G는 고루틴, M은 머신(OS레벨 스레드), P는 proccessor를 의미합니다. 그림에서는 쉽게 표현하기 위해 저렇게 도식화했지만 실제 1:1:1 매핑은 아닙니다.
고루틴 스케쥴러에 의해 고루틴이 Machine에 할당될 때 Processor에 의해 매칭되는데 이 때 각 Processor에 해당되는 즉, LRQ(Local Run Queue)에 고루틴이 있다면 여기 있는 고루틴 작업을 하게 되고, 없다면 GRQ(Global Run Queue)에 있는 고루틴 작업을 수행하게 됩니다. 고루틴에 의한 비동기적 처리는 해당 함수 앞에 go를 표기하므로서 간단하게 고루틴을 사용할 수 있습니다.
그렇다면, Virtual Thread, Corutine, Gorutine은 뭐가 다른걸까?
발표 준비 기간과 발표 당시에 여러 언어 현업자들과 함께 이 부분에 대해 논의를 많이 해봤습니다. 그런데 결과적으로 뚜렷하게 이 언어의 경량스레드 모델이 다른 것과 다소 차이는 있고 어떤 상황에서 저걸 사용하는게 좋다라는 의견을 제시할 수는 있었지만 제가 생각하는 것만큼 명확한 답을 내리지 못했었습니다. 그래서 발표 때 비교장표를 보여드릴 수 없어서 아쉬웠습니다. 발표가 끝나고 이 부분에 대해 더 알아보고 내린 결론은 좀 더 OS Thread에 밀접한 연관이 있고 기존 프로젝트가 Java을 사용하는 언어에서는 Virtual Thread를 빠르게 도입하는 것이 유리합니다. Corutine, Gorutine은 경량 스레드라고 불리지만 결국에는 비동기적 측면에 Virtual Thread는 아이에 Thread를 확장한 개념으로서 서버 사이드적 측면에서 접근해야 한다는 결론에 도달했습니다.
- Virtual Thread는 Blocking I/O가 발생되는 경우, Virtual Thread가 새로 생성되기 때문에 문제가 되지 않습니다. Carrier Thread를 yield하고 자신이 가진 정보를 heap에 올리기 때문입니다.
Instead, virtual threads automatically give up (or yield) their carrier thread when a blocking call (such as I/O) is made. This is handled by the library and runtime [...]
- 코루틴은 이벤트 핸들링 처리에서 상태 업데이트에 Blocking I/O가 존재하는 경우, main thread가 영향을 받거나 다른 응답처리가 안될 수 있습니다.
Channel
Go 언어는 “Do not communicate by sharing memory, share memory by communicating”라는 철학에 따라 설계되었습니다. 통신에 의한 메모리 공유라는 핵심철학을 가지고 있고 이 원칙은 고루틴들이 직접 메모리를 공유하고 않고, 대신 채널을 통해 메시지를 주고 받으며 데이터를 교환한다는 의미입니다. 채널은 고루틴들 사이에서 데이터를 안전하게 전송할 수 있는 파이프라인으로 데이터 경합 발생가능성을 줄이고, 순차처리를 통해 안전한 데이터 교환이 가능하게 합니다. 또한 채널을 사용하므로서 데이터 흐름을 명확하게 볼 수 있고 디자인 패턴 구현이 다양해집니다. Go 언어의 기본적인 동시성 패턴으로 Worker pool pattern, Pipe pattern, Fan-out/Fan-in pattern 등을 가지고 있는데 대표적인 이 3가지 패턴의 특징은 다음과 같습니다.
Worker pool pattern
스레드 풀과 유사한 개념으로 일정 수의 고루틴(워커)를 생성하여, 작업 큐에서 작업을 가져와 처리하는 구조입니다. 이 패턴은 리소스 사용을 효율적으로 관리하고, 고루틴 생성과 종료에 따른 오버헤드를 줄일 수 있습니다. 워커 풀은 병렬 작업 처리에 특히 유용합니다.
Pipe pattern
일련의 처리 단계를 통해 데이터를 전달하는 방식으로 순차적 전달되므로 그 데이터 흐름을 파악하는데 유용합니다. 각 단계는 채널을 받아서 다음 단계에 채널을 리턴하는 방식으로 진행됩니다.
Fan-out/Fan-in pattern
Fan-out/Fan-in은 특히 다량의 데이터 처리나 복잡한 연산을 병렬로 수행하고 결과를 집계할 때 유용하며, 워커 풀 패턴보다 동적으로 고루틴을 생성하고 관리하는 경향이 있습니다.
Typescript와 동시성 프로그래밍
Typescript는 타입이 들어간 JavaScript의 상위 집합 언어로 JavaScript의 동시성 모델을 따릅니다.
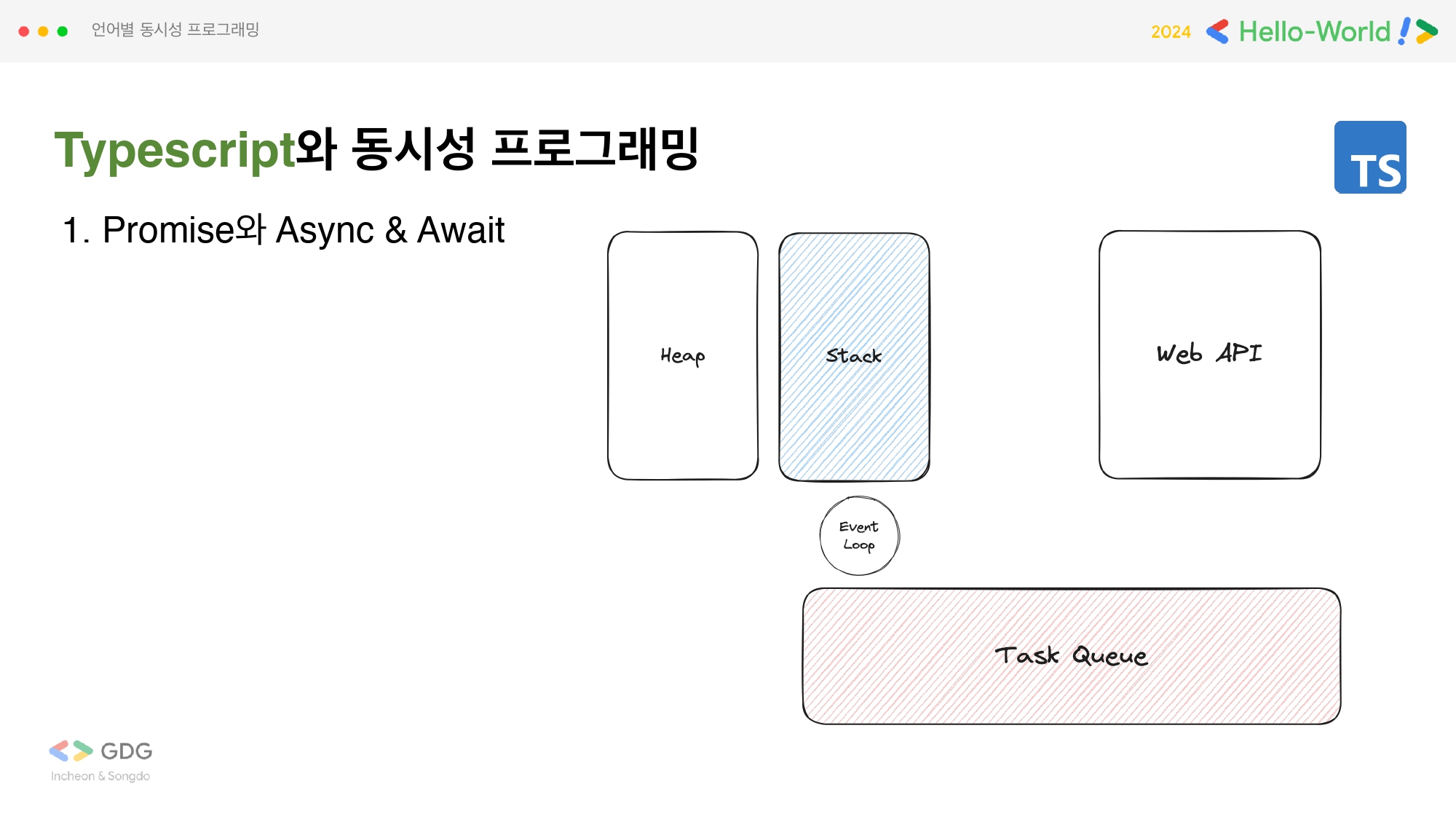
브라우저 동작원리
먼저, 일반적인 브라우저 동작원리를 먼저 살펴보겠습니다. 브라우저는 필요한 변수 등을 Heap에 담아두고 console에 출력하는 등의 간단한 실행은 Stack에 두고 하나씩 실행됩니다. 하지만 Web API를 사용해야 하는 경우에는 Task를 Task Queue에 쌓아두고 Stack이 비었을 때 Event loop를 통해서 실행되게 됩니다. 즉, 싱글 스레드 조건에서 비동기 프로그래밍을 가능하게 하는 건 바로 Task Queue가 있기 때문입니다. (Web API의 예로는 setTimeout, ajax 등이 있습니다.)
브라우저에서 JavaScript 코드가 실행될 때, 비동기 작업을 처리하기 위해 Promise와 Await를 사용할 수 있습니다. 예를 들어, 웹 페이지가 로드될 때 이미지를 비동기적으로 다운로드하고, 다운로드가 완료되면 화면에 표시할 수 있습니다.
Promise는 미래에 완료될 작업을 대표하는 객체이며, 성공 또는 실패의 결과와 함께 처리될 수 있습니다. Await는 프로미스 기반의 비동기 작업을 보다 동기적으로 보이는 코드 스타일로 작성할 수 있게 해 주는 문법적 설탕(syntactic sugar)입니다. 코드의 가독성과 유지보수성을 향상시킬 수 있지만, Promise chaining 이슈와 콜백 지옥 가능성을 완전히 배제할 수는 없습니다.
Swift와 동시성 프로그래밍
Swift에서는 WWDC에서 언급된 Swift concurrency을 중심으로 정리했습니다.
Grand Central Dispatch
GCD는 Grand Central Dispatch로 뉴욕의 기차역 그랜드 센트럴 터미널의 이름에서 유래한 것으로 GCD는 다양한 멀티스레딩 작업을 쉽게 관리할 수 있는 API를 제공합니다. 쉽게 말해 비동기 상황에서 GCD는 여러 Task를 여러 스레드에 분배하는 역할을 합니다.
그럼 이 디스패치 큐는 한 종류인가? 아닙니다. Main, Global, Custom 큐들이 있는데 이 중에서 Global 큐과 설정에 따라 Custom 큐는 Concurrent Queue로 사용될 수 있습니다. Concurrent Queue는 여러 work item 을 한 번에 처리할 수 있기 때문에, 모든 CPU 코어가 포화될 때까지 시스템은 여러 스레드를 불러옵니다. 여기서 잘못된 스레드 관리와 코드 설계는 Thread explosion으로 코어를 넘어가는 스레드 생성이 비효율을 발생시킬 수 있습니다.
Swift concurrency
언어 수준에서 비동기 작업을 지원하기 위한 것으로 GCD와는 차이가 있습니다. GCD는 저수준의 C언어 기반 API로 직접 CPU 및 스레드를 이용하기 때문입니다. Task, Actor는 언어 레벨에서 동시성을 다루기 때문에 디버깅과 흐름을 파악하는데 좀 더 용이합니다.
Task
Task는 Swift 5.5에서 도입된 async/await 문법을 사용하여 비동기 코드를 작성할 수 있는 고수준 추상화입니다. Task는 실행 중인 작업을 취소할 수 있는 기능을 제공합니다. 이는 비동기 작업을 중단하고 관련 리소스를 해제하는 데 유용합니다. async/await 만을 사용할 때는 호출을 위한 async 처리를 호출을 하는 곳에서도 처리를 하는 등 번거로운 점이 있었지만, Task 사용으로 각 Task별로 독립적으로 비동기 작업 수행이 가능해집니다.
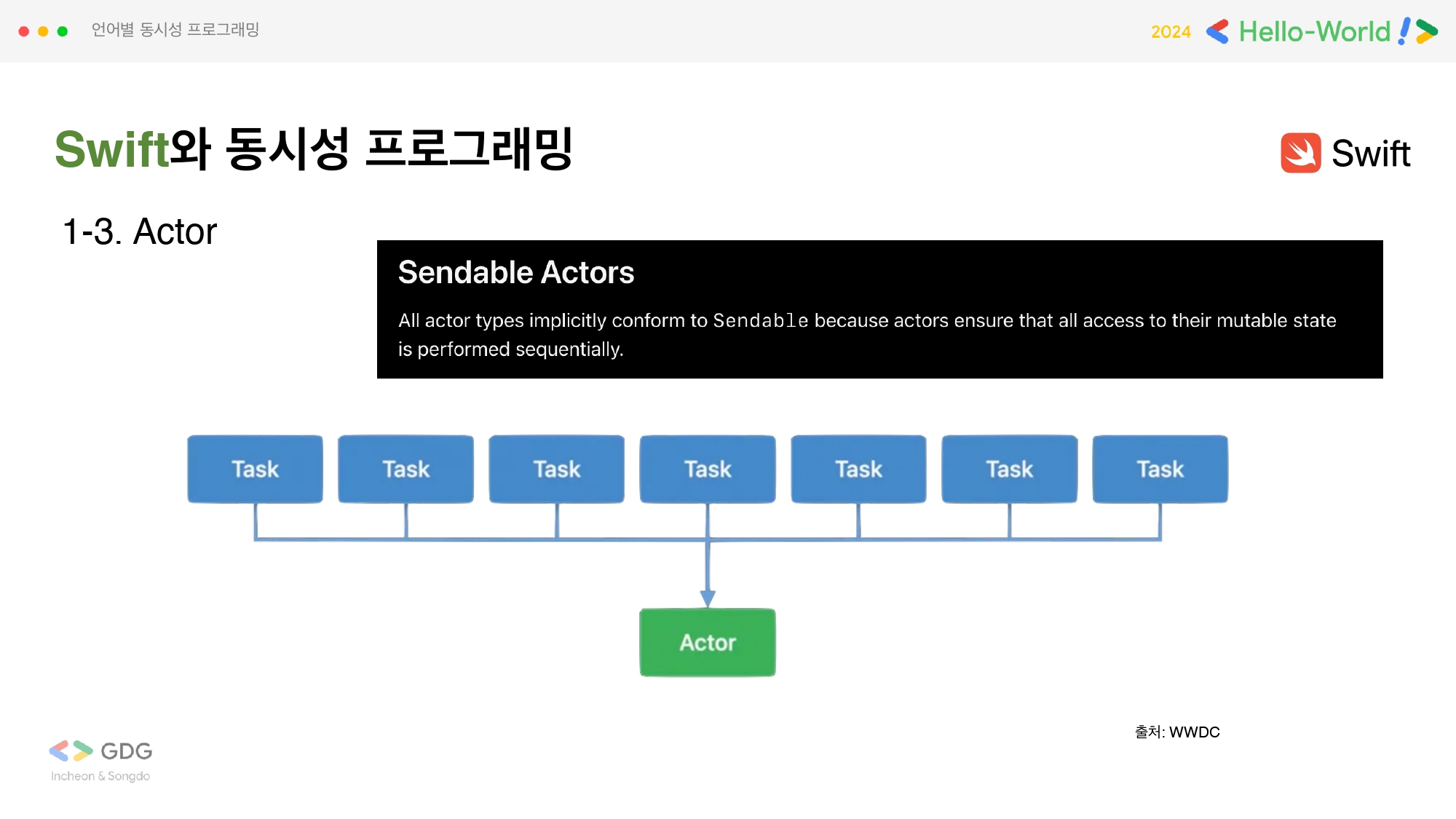
Actor
상태를 안전하게 캡슐화하고, 동시성 접근을 관리하는 고수준 추상화로 Task를 직렬화해서 한 번의 한 Task만 Actor 타입 접근을 가능하게 합니다. 접근시에도 내부 값들은 isolated 상태로 self 참조로 접근을 할 수 있게 한다는 특징이 있습니다. 따라서 Data race를 유발하지 않는다는 장점이 있습니다.
Dart와 동시성 프로그래밍
Future
비동기 결과의 값, 즉 미래의 값을 갖는 추상적인 클래스입니다. 자바스크립트 Promise와 유사하며, 단일 비동기 작업의 결과에 따라 추가 작업을 연결할 수 있는 체이닝(chaining) 메커니즘을 제공합니다. Dart의 Future에서는 then, catchError, whenComplete 메서드가 있습니다.
Stream
연속적인 이벤트를 처리하는 데 사용됩니다. Stream 자체는 다른 언어에서도 이벤트 처리르 위해 많이 사용되는 개념으로 시간의 지남에 따라 발생하는 이벤트 처리가 가능해집니다. listen 메서드로 이벤트를 수신하고 처리할 수 있습니다.
isolate
각각의 isolate는 독립적인 메모리 공간을 가지고 channel로만 통신을 하는 컨텍스트입니다. 주로 긴 시간이 걸리는 작업을 처리하거나 정책상 관심사 분리를 위해 현업에서 선택하는 경우가 있다고 들었습니다. isolate를 사용하게 되면 아이에 다른 pid를 가지기 때문에 완벽한 분리가 이뤄지지만, 이 정도의 분리가 필요한 작업인 경우에 다른 모듈 또는 프로젝트로 구성하는 경우도 많기 때문에 isolate를 사용하는 경우는 실제 많지 않다고 합니다.
발표 내용을 정리하면서
발표주제로 너무 크고 다양한 언어의 차이?를 다루려는 욕심에 개개의 언어에서의 동시성에 대한 부분을 더 다루지 못했다는 부족함이 있었습니다. 개인적으로도 모든 언어를 다 현업에서 다뤄보지 않았었기 때문에 엄청난 확신과 자신감에 찬 발표를 준비하지 못했기에 아쉬움이 남습니다. 하지만 이런 기회가 없었다면 백엔드 개발자라는 틀에 갇혀서 다른 언어에 대한 고민이나 생각들을 하지 못했을 것 같습니다. 올해는 다양한 언어를 다뤄보고 제 스택은 좀 더 깊이 있게 고민해볼 수 있는 계기를 만들어 보겠습니다! 🫡
- Project loom, what happens when virtual thread makes a blocking system call?
- Coroutines and Loom behind the scenes by Roman Elizarov
인증과 인가
Authentication 인증은 접근 자격이 있는지 신원을 검증하는 단계이고,
Authorization 인가는 특정 자원에 접근할 권한을 부여하는 것을 말합니다. 인가가 완료되면 access token이 클라이언트에 부여됩니다.
OAuth와 로그인은 분리해서 생각해야 한다구?
OAuth를 이용한 인증은 허가의 의미도 포함하고 있으며, 제3자가 사용자의 권한으로 접근하는 것을 허용해주는 방식입니다. 따라서 그 서비스에 직접 로그인한 사용자와 달리 ‘방문증’을 가지고 있는 것이라고 생각하면 이해하기 쉽습니다. 그래서 우리는 흔히 일반적으로 회원가입 후 OAuth 인증을하는 방식으로 계정을 연동하는 것을 볼 수 있습니다.
OpenID도 있는데 어떻게 다른걸까?
OpenID의 주요 목적은 인증(Authentication)이지만, OAuth의 주요 목적은 허가(Authorization)입니다. OAuth도 인증과정이 있지만 근본 목적은 API를 호출할 수 있는 권한이 있는 사용자인지를 확인하는 것입니다.
OAuth
Open Authorization
타사 애플리케이션 계정 정보를 공유해 비밀번호 없이 토큰으로 접근권한을 위임하는 개방형 표준 입니다. 만약 사용자가 구글 계정으로 로그인을 하게 되면 로그인 정보를 가지고 계정과 연결된 구글의 API를 가지고 Google Calendar와 같은 정보를 가지고 와서 사용할 수 있습니다. 이렇게 사용자를 인증을 하는 과정을 OAuth Dance라고 합니다.
OAuth와 OAuth 2.0
OAuth 1.0이 나온 때는 2007년이며, 이후 보안 문제를 해결한 수정 버전인 OAuth 1.0 revision A가 2008년에 나왔습니다.
이후 나온 OAuth 2.0은 기능적으로도 규모적으로 확장된 형태로 다양한 인증방식을 제공합니다. OAuth 2.0은 OAuth과 호환되지 않지만 인증절차가 간단합니다. access token도 기존에는 계속 사용이 가능했으나, 2.0이 되면서 보안 강화를 위해 Life-time을 설정해두고 있습니다.
그리고 별도의 암호화가 필요없고 HTTPS를 사용하기 때문에 데이터는 SSL/TLS 프로토콜을 사용해 암호화됩니다.
기존 OAuth에서는 Signature 단순화 정렬과 URL 인코딩하는 과정이 있었지만, 2.0에서는 필요없어졌습니다. 대신 클라이언트 인증방식으로 Authorization Code Grant, Implicit Grant, Client Credentials Grant, Resource Owner Password Credentials Grant 등을 제공하고 있기 때문입니다.
따라서 기존 1.0에서 사용된 HMAC(SHA-1)도 사용하지 않습니다. 이는 클라이언트 인증과 서명 메시지 생성에 사용됐었던 알고리즘입니다.
OAuth의 작동방식
User - Consumer - Service Provider
- Consumer는
Request Token요청하고 Service Provider가 발급 - 사용자 인증페이지에서 사용자 로그인
- 사용자 권한 요청 및 수락
Access Token이 발급 및 API 서비스 정보 요청
OAuth 2.0의 작동방식
User(Resource Owner) - Client Server - Resource Server
- User가 소셜 로그인을 하면 연동 서비스 로그인 페이지에서 로그인을 하고 접근권한 제공여부를 확인
- 동의를 한 경우, Resource Server에서 Client ID, Secret과 Redirect URL이 일치하는지 검사
- Resource Server는
Authorization Code제공 - Client는 다시 3번의 토큰과 정보를 넘기고
Access Token발급요청 - Resource Server는
Access Token발급 - API 호출시 유효한
Access Token인 경우 Resource 제공
소프트웨어 개발 방법론
객체 지향 방법론
객체지향 설계 원칙 (= SOILD)
5대 설계원칙: SRP, OCP, LSP, ISP, DIP
SRP(Single Responsibility Principle), 단일 책임 원칙
한 클래스는 하나의 책임만 가져야 한다는 원칙입니다.
아래 코드에서도 볼 수 있듯이 사용자와 관련된 로직과 이메일 발송에 대한 로직을 따로 분리해서 class화 하는 것이 바람직합니다. 단 하나의 책임만 가질 수 있도록 코드를 분리해서 작성하도록 합니다.
class User {
fun register() { }
}
class EmailSender {
fun sendEmail() { }
}
OCP(Open/Closed principle), 개방-폐쇄 원칙
소프트웨어 요소는 확장에는 열려 있으나 변경에는 닫혀 있어야 한다는 원칙입니다.
Dog 클래스와 Cat는 둘 다 Animal 리턴 타입을 반환하는 makeSound() 메서드는 사용합니다. 여기서 Animal 클래스는 OCP 원칙을 지킨 클래스인데, 다른 동물 클래스를 만들 때에도 변경 없이 반환 타입 클래스로 동일하게 사용이 가능합니다.
// 동물 클래스
open class Animal(val name: String) {
open fun makeSound() {
println("동물이 소리를 내지 않습니다.")
}
}
// 개 클래스
class Dog(name: String) : Animal(name) {
override fun makeSound() {
println("멍멍!")
}
}
// 고양이 클래스
class Cat(name: String) : Animal(name) {
override fun makeSound() {
println("야옹~")
}
}
LSP(Liskov Substitution Principle), 리스코프 치환 원칙
프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 합니다.
예시에서 보면 TransactionalAccount 클래스에서 상위 클래스 Accout의 메서드인 deposit()를 오버라이드해서 하위 타입의 인스턴스에 사용할 수 있음을 알 수 있습니다.
// 계좌 클래스
open class Account(val accountNumber: String, var balance: Double) {
open fun deposit(amount: Double) {
balance += amount
println("$amount 원이 입금되었습니다. 현재 잔액: $balance 원")
}
}
// 입출금 계좌 클래스
class TransactionalAccount(accountNumber: String, balance: Double) : Account(accountNumber, balance) {
override fun deposit(amount: Double) {
super.deposit(amount)
println("거래 내역이 저장되었습니다.")
}
}
// 메인 함수
fun main() {
val account: Account = TransactionalAccount("1234567890", 50000.0)
account.deposit(10000.0)
}
ISP(Interface Segregation Principle), 인터페이스 분리 원칙
특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다는 원칙으로 큰 덩어리의 인터페이스들은 구체적이고 작은 단위들로 분리시킴으로써 클라이언트들이 꼭 필요한 메서드들만 이용할 수 있게 합니다.
아래 예시는 ISP 원칙을 위반한 인터페이스로 모든 동물이 날지 않기 때문에 모호하고 경우에 따라 꼭 필요한 메서드가 아닌 fly()를 포함하고 있습니다.
// 헷갈리는 동물 인터페이스
interface ConfusingAnimal {
fun eat()
fun fly()
}
DIP(Dependency Inversion Principle), 의존관계 역전 원칙
프로그래머는 추상화에 의존해야지 구체화에 의존하면 안된다는 원칙입니다. 하위모듈의 구체적인 내용에 클라이언트가 의존하게 되면, 하위 모듈의 변화가 있을 때마다 클라이언트나 상위 모듈을 수정해줘야 한다는 단점이 발생하기 때문입니다.
아래 예시는 BulbController 클래스는 Bulb 인터페이스를 상속받아서 만들어졌고, 메서드에서 인터페이스의 메서드들을 사용하는 의존관계 역전 현상을 보여주고 있습니다.
// 전구 인터페이스
interface Bulb {
fun turnOn()
fun turnOff()
}
// 전구 컨트롤러 클래스
class BulbController(private val bulb: Bulb) {
fun pressSwitch() {
bulb.turnOn()
bulb.turnOff()
}
}
DDD(Domain-Driven Design)

도메인 주도 설계는 소프트웨어의 존재 가치는 사용자의 사용에 있다는 생각에서 비롯되어 비즈니스 도메인을 중심으로 고려한 설계 방식입니다. 즉, 사용자가 원하는 목적에 맞게 사용할 수 있는 소프트웨어가 기술보다 우선순위에 두고 고민할 필요성이 있다는 점에서 시작됩니다. 사용자의 관점에서 정해지는 부분이기 때문에 도메인은 관점에 따라 그 수가 달라질 수 있습니다. 하지만 DDD를 사용하므로써 개발자는 단순히 기술영역에만 국한되지 않고 도메인 영역까지 사고하는 생각의 범주를 더 넓힐 수 있습니다.
바운디드 컨텍스트란 모델이 구현되는 곳이자 각각의 분리된 소프트웨어 산출물이 나오게 되는 곳입니다. 유비쿼터스 언어로 표현해 공동 작업을 하는 팀원과 유관 부서 간의 혼동을 피하는 것을 기본으로 합니다.
반 버논의 도메인 분류
- 메인(핵심) 도메인
- 서브 도메인
- 핵심 서브 도메인
- 다른 경쟁자와 차별화를 만들 수 있는 비즈니스 영역
- 높은 우선순위를 갖는 전략적 투자 영역
- 가장 큰 투자가 필요한 곳
- 지원 서브 도메인
- 맞춤 개발이 필요한 영역
- 핵심 서브 도메인의 성공을 위한 중요한 영역
- 일반 서브 도메인
- 기존 제품 구매를 통해 바로 충족시킬 수 있는 영역
- 핵심/지원 서브도메인이 할당된 팀에서 직접 구현 가능
- 핵심 서브 도메인
Domain-Driven Design Simplified.
도메인 주도 설계에서의 전략적 설계
Type System
강타입 언어는 타입 검사를 통과하지 못하면 컴파일 에러로 프로그램의 실행 자체를 막지만, 약타입 언어는 런타임시 타입오류가 있어도 실행을 막지 않습니다. 대부분의 강타입 언어에서는 int, char와 같은 타입 선언을 하지만, 약타입은 하지 않습니다. 하지만 Haskell의 경우에는 컴파일러가 ‘추론’을 통해 검사를 하기 때문에 약타입처럼 보이지만 강타입 계열에 속합니다.
- 강타입
GO,ML,F# - 강타입 계열
C#,Haskell,Java - 약타입 계열
Javascript,Assembly
컴파일시 타입이 결정되는 정적타입 언어는 강타입 계열에 해당합니다. 반면, 동적타입(Dynamically typed) 언어는 주로 약타입이지만 런타입에서 변수의 타입이 결정되기 때문에 강타입 계열 언어가 될 수 있습니다. 타입에 대한 의견은 다양하지만 동적타입 언어가 타입힌트와 타입 어노테이션을 가지고 강력한 타입체크를 한다면 가능한 의견입니다.
C, C++는 강타입이 아니다?
타입 검사를 통과하지 못하면 항상 실행이 되지 않아야 하지만, union 타입에서는 타임에러를 검출할 수 없기 때문입니다. 따라서 강타입 ‘계열’의 언어로 보는 것이 바람직합니다.
정적타입 언어는 코드작성이 빠르고 유연성이 높기 때문에 개발자가 효율적으로 작업할 수 있지만, 런타입 에러가 발생하거나 디버깅이 어렵다는 단점이 있습니다. 반면, 정적타입 언어는 컴파일 에러가 발생하기 때문에 타입에러를 미리 잡아 안정성이 높다고 할 수 있습니다. 하지만 코드 작성이 더 복잡하고 유연성이 낮다는 단점이 있습니다.
Toggle the table of contents Strong and weak typing
테스트 더블
Dummy, Stub, Fake, Spy, Moke
테스트 더블은 xUnit의 저자 Gerard Meszaros가 만든 용어로, 스턴트 더블(스턴트 대역 배우를 지칭하는 용어)에서 아이디어를 얻은 말이라고 합니다. 실제 DOC 접근이 어렵고, 사용할 수 없는 경우에 사용되는 Test 객체입니다.
테스트 더블을 이용하면, 테스트 대상 코드를 격리하고 테스트 속도를 개선할 수 있습니다. 그리고 특수한 상황을 시뮬레이션 할 수 있습니다.
Dummy
실제로 사용되지는 않지만 파라미터 리스트를 채우기 위해 사용되는 객체를 말합니다. 구현을 제외한 인터페이스 또는 기본 클래스의 파생 객체로 객체만 전달될 뿐 사용되지 않습니다.
아래 코드에서 보면, DummyObject는 아무것도 없지만 @Test 파라미터를 채우기 위해 존재하는 객체로 이름만 존재하는 것을 알 수 있습니다.
public class DummyObject {}
public class DummyObjectTest {
@Test
public void testDummyObject() {
DummyObject dummy = new DummyObject();
// 테스트할 로직 작성
}
}
Stub
Dummy 객체가 실제로 동작하는 것처럼 보이게 만들어 놓은 객체를 말합니다. 호출자를 실제 구현물로부터 격리시키는 목적으로 사용합니다. 테스트에서 호출된 요청에 대해 미리 준비해 둔 결과를 제공합니다.
public interface DatabaseService {
String getData();
}
public class DatabaseServiceStub implements DatabaseService {
@Override
public String getData() {
return "Stubbed data";
}
}
public class MyClassTest {
@Test
public void testMethodWithStub() {
DatabaseService databaseStub = new DatabaseServiceStub();
MyClass myClass = new MyClass(databaseStub);
// Call the method that uses the stubbed database service
String result = myClass.processData();
// Assert the result
assertEquals("Stubbed data", result);
}
}
Fake
in-memory test database가 대표적인 사례로 실제로 동작하진 않지만 정해진 결과값을 리턴하도록 하드코딩된 객체를 말합니다. 그렇기 때문에 구현은 가지고 있지만 실제 사용하는 객체처럼 보일 뿐, 실제 객체의 동작과는 차이가 있습니다.
public interface EmailService {
void sendEmail(String to, String message);
}
public class FakeEmailService implements EmailService {
private List<String> sentEmails = new ArrayList<>();
@Override
public void sendEmail(String to, String message) {
// 이메일을 실제로 보내지 않고, 리스트에 추가한다.
sentEmails.add(to + ": " + message);
}
public List<String> getSentEmails() {
return sentEmails;
}
}
public class FakeEmailServiceTest {
@Test
public void testFakeEmailService() {
FakeEmailService fakeEmailService = new FakeEmailService();
// 테스트할 로직 작성
}
}
Spy
테스트에서 특정 객체가 사용되었는지 그 객체의 예상된 메서드가 정상적으로 호출되었는지 확인해야하는 상황이 생기는 경우에 사용합니다.
public class SpyList extends ArrayList<String> {
private boolean addMethodCalled = false;
@Override
public boolean add(String element) {
addMethodCalled = true;
return super.add(element);
}
public boolean isAddMethodCalled() {
return addMethodCalled;
}
}
public class SpyListTest {
@Test
public void testSpyList() {
SpyList spyList = new SpyList();
// 테스트할 로직 작성
}
}
Mock
어떤 동작을 했을 때, 어떤 결과를 주는지에 대해 프로그래밍된 객체를 말합니다. MockPaymentGateway는 실제 프로그램에서 사용되는 객체로 그 객체를 가지고 와서 테스트하기 때문에 실제 프로세스가 구현이 되어 잘 동작하는지 확인할 수 있습니다.
public interface PaymentGateway {
boolean processPayment(double amount);
}
public class MockPaymentGateway implements PaymentGateway {
private boolean processPaymentCalled = false;
@Override
public boolean processPayment(double amount) {
processPaymentCalled = true;
// 실제 결제 프로세스를 모킹하여 테스트에 사용한다.
return true;
}
public boolean isProcessPaymentCalled() {
return processPaymentCalled;
}
}
public class MockPaymentGatewayTest {
@Test
public void testMockPaymentGateway() {
MockPaymentGateway mockPaymentGateway = new MockPaymentGateway();
// 테스트할 로직 작성
}
}
그럼 언제 어떤 테스트 더블을 사용해야 할까?
쓰임에 따라 사용해야할 테스트 더블은 다른데, Mockist TDD의 경우에는 Mock만을 사용하고, Classicist TDD의 경우에는 Fake, Stub, Spy를 사용하는 것이 적절하고 경우에 따라서는 Mock도 사용할 수 있습니다. Mockist과 Classicist에 대해서는 아래 작성한 글을 참고해주세요.
TestDouble - Martin Flower
Test Double(테스트 더블)알아보기
TDD: Test Doubles in Unit Testing. Should we use Fakes? Stubs? Mocks?
Mockist vs Classicist
먼저 알고가야할 개념이 있습니다. 테스트 더블을 사용해서 실제 의존 클래스로부터 격리된 테스트인 Solid Unit Test를 구축하는 방법과 테스트 더블을 사용하지 않는 Sociable Unit Test 테스트 방법이 있습니다. 이러한 개념들은 XP(Extreme Programming)을 기반으로 시작된 TDD를 어떻게 진행해야 하는가에서 시작되었습니다.

Solitary를 지향하는 사람들을 Mockist라고 하고, Sociable한 테스트도 괜찮다고 생각하는 사람들을 Classicist라고 합니다.
Mockist TDD
London School Strategy, Interaction Testing, Outside-In, white box testing이라고도 알려져 있는 Mockist TDD는 SUT를 생성하고 더블로 Mock를 사용합니다.
SUT(System Under Test)이란?
하나의 테스트에서 테스트하고자 하는 주요 대상이 되는 Unit인 테스트 대상 클래스입니다.
verify(mockWareHouse).remove('식빵', '딸기쨈', '우유'); // 행위검증, test 안정감 낮음
테스트를 위한 사전작업으로 Mock 객체를 이용한 방법을 SUT와 직접적인 협력을 맺고 있는 객체 메서드만 설정해주면 됩니다.
Order mockOrder = mock(Order.class);
given(mockOrder.isPossible()).willReturn(true);
재고확인 - 유통기한 확인 - 재고 줄이기 - 주문 유효성 검증이 순서로 재고를 확인한다고 했을 때 여기서 추가로 중간에 구현된 유통기한 확인에 대한 부분에 대해서는 테스트가 깨지기 때문에 Classicist와 달리 변경이 필요합니다. 반면, 테스트 세분화를 하기 쉬운 환경으로 어디서 발생한 버그인지를 찾기 더 유리할 수 있습니다.
Classicist TDD
Detroit School strategy, Inside-Out, black box testing라고 알려져 있으며, 시스템 바운더리 안에서 테스트를 진행하는 스타일입니다. 모든 테스트 더블을 사용하는게 가능하지만, 만약 SUT와 collaborator 사이의 collaboration으로 확인이 불가한 경우에는 mock를 사용하기도 합니다.
assertThat(wareHouse.size()).isEqualTo(1); // 상태검증, test 안정감 높음
테스트를 위한 사전작업으로 Fixture를 만드는 과정을 예시코드로 살펴보면, Classicist에서는 실제 필요한 협력객체를 만들어주는 것을 볼 수 있습니다.
List<Item> orderItems = List.of(new Item('식빵'), new Item('딸기'), new Item('우유'));
Inside-Out 방법을 사용하기 때문에 객체간 협력이 어색하거나 public api가 잘못 설계될 수 있다는 단점이 있습니다.
UnitTest - Martin Flower
Classicist TDD vs Mockist TDD
Mockist vs Classical testing strategy
[10분 테코톡] 더즈, 티키의 Classic TDD VS Mockist TDD