JPA
- 📖 스프링 부트와 JPA 실무 완전 정복 로드맵
- JPA에 대하여
- 영속성 컨텍스트(persistence context)
- 데이터베이스 스키마 자동생성
- 엔티티 매핑
- 🚴🏽 JPAQueryFactory 설정 이슈
JPA에 대하여
JPA는 Java Persistence API로 자바 플랫폼 SE와 자바 플랫폼 EE를 사용하는 응용프로그램에서 관계형 데이터베이스의 관리(ORM 기술 표준)를 표현하는 자바 API입니다. 여기서 ORM(Object Relational Mapping)이란 객체와 데이터베이스의 관계를 매핑해주는 도구로 자바 외 언어에서는 node.js에서의 Sequelize, python 기반 Django에서 지원하는 Django ORM 등이 있습니다.
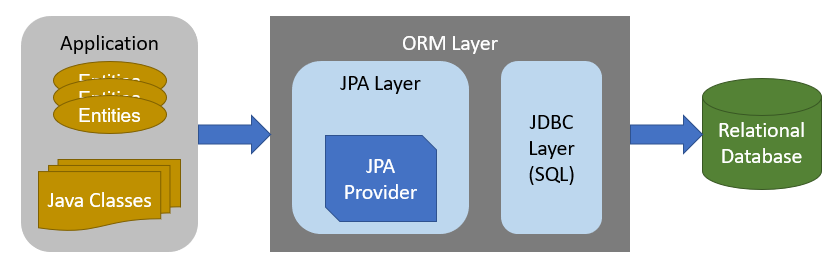
JPA는 애플리케이션과 JDBC 사이에서 동작하며 SQL 작성으로 인한 개발시간을 단축할 수 있다는 장점이 있습니다. JPA를 사용하면 Entity 분석하고 SQL 생성한 뒤, JDBC API 사용하고 패러다임의 불일치까지 해결해 줄 수 있습니다.
JPA는 패러다임의 불일치를 어떻게 해결할까?
패러다임의 불일치는 객체와 관계형 데이터베이스 사이의 불일치 의미합니다. 관계형 데이터베이스에는 테이블로 데이터를 관리하고 객체 지향 프로그래밍은 객체 단위로 상속, 다형성 개념을 가지고 관리합니다. 대표적인 불일치로 사례들은 상속, 연관관계, 객체 그래프 탐색, 식별자 등이 있습니다. JPA에서는 다양한 매핑 어노테이션과 매핑 설정, 그리고 지연로딩, 즉시로딩을 이용해 패러다임의 불일치를 최소화하고 있습니다.
JPA 성능 최적화 기능
1차 캐시와 동일성 보장합니다. 같은 트랜잭션 안에서 같은 엔티티를 반환하고 Read Commit 격리수준에서도 애플리케이션에서 Repeatable Read를 보장합니다.
트랜잭션을 지원하는 쓰기 지연을 제공합니다. 트랜잭션이 끝날 때까지 Insert SQL을 모아서 한 번에 Commit 처리합니다.
지연로딩과 즉시로딩을 지원합니다. 연관된 객체까지 미리 조회하는 것을 즉시로딩이라고 합니다. 반면, 지연로딩은 객체가 실제 사용될 때 로딩되는 방식입니다.
데이터 중심 설계와 엔티티 설계의 차이점
데이터 중심 설계는 테이블의 외래키를 객체에 그대로 가지고 오는 방식으로 만들어져 있습니다. 이렇게 하게 되면, 객체 그래프 탐색이 불가능해지고, 참조가 없어 UML도 잘못 작성됩니다.
따라서 먼저 자바 객체인 엔티티를 설계하고 테이블을 생성하는 방식을 사용해야 합니다. 외래키가 아닌 참조할 키의 값을 가지고 와서 하나의 컬럼
Spring Data JPA - Reference Documentation
영속성 컨텍스트(persistence context)
JPA의 모든 기능은 Transaction 안에서 수행해야 합니다.
이는 JPA가 영속성 컨텍스트(persistence context)를 사용하여 엔티티의 상태를 추적하고, 데이터베이스와의 일관성을 유지하기 위해 필요합니다. 영속성 컨텍스트는 JPA에서 엔티티 객체를 관리하는 메모리 영역이며, 엔티티의 상태를 추적하고 변경사항을 데이터베이스에 반영합니다. 트랜잭션을 사용하지 않으면 영속성 컨텍스트가 데이터베이스와의 일관성을 유지할 수 없게 되어, 데이터 불일치 문제가 발생할 수 있습니다.
영속성 컨텍스트를 사용하므로써 1차 캐시에서 조회한 뒤, 없으면 DB 조회하고 1차 캐시에 반영합니다. 그리고 요청값을 반환합니다. 즉, 1차 캐시로 Repeatable Read 등급의 트랜잭션 격리수준을 애플리케이션 차원에서 한 트랜잭션 안에 수행하며, 매번 사용되는 것이 아니라 큰 성능상의 이점은 없지만, 한 트랜잭션이 길고 반복조회가 많다면 1차 캐시를 이용한 영속성 컨텍스트의 효과를 볼 수 있습니다.
(참고로 모든 고객이 같은 캐시로 성능적 효과를 보는 것은 이와 별개로 2차 캐시라고 합니다.)
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin();
em.persist(memberA);
em.persist(memberB);
transaction.commit();
// em.persist(memberA); 첫 번째 SQL만 생성되서 조회하는 것을 확인할 수 있습니다.
// 이후 내용은 1차 캐시에서 조회하기 때문
em.detach(member); // 준영속, 영속성 컨테스트에서 분리
em.remove(member); // 객체를 삭제한 상태
준영속 상태란?
JPA가 관리하는 상태인 1차 캐시에 있는 상태는 영속성 상태라고 할 수 있습니다. 반면, 준영속 상태는 영속성 컨텍스트에서 분리된 것으로 JPA가 관리하는 상태가 아닙니다. 따라서 항상 변경 감지를 사용해서 entity를 관리할 필요가 있습니다. 실무에서는 데이터베이스의 특정 테이블에 대한 일시적인 변경이 필요한 경우, 준영속 상태를 사용하여 일시적 변경 후 되돌리는 경우가 있습니다.
영속성 컨텍스트의 이점
1차 캐시만을 사용하며, 영속성 컨텍스트는 조회시 같은 객체를 불러온다는 점에서 동일성을 보장해줍니다. 트랜잭션을 지원하는 쓰기지연으로 영속성 컨텍스트를 플러시하기 전까지 데이터베이스 락이 걸리는 시간을 최소화합니다. 지연로딩을 이용해서 연관관계를 패러다임 불일치를 감소시킵니다. 그리고 변경감지(dirty check)를 하기 때문에 스냅샷 정보와 바뀐 entity 정보를 비교해서 변경 부분을 커밋시에 업데이트해줍니다.
쓰기 지연 SQL 저장소는 왜 필요할까?
쓰기 지연은 한 트랜잭션에서 일어나는 update, save 쿼리를 가지고 있다가 최종적으로 commit이 일어나는 시점에 한 번에 DB에 반영하는 것을 말합니다. Persistance Storage는 이런 쓰기 지원 기능을 가지고 있습니다. 따라서 Persistance Context 하에 관리되고 있던 entity의 변화들을 감지, 추적하고 이를 Persistance Storage에 반영한 뒤 최종적으로 DB에 반영할 수 있도록 합니다.
플러시가 뭘까?
영속성 컨텍스트의 변경내용을 데이터베이스에 반영하는 것을 말합니다. 커밋이나 쿼리 실행시 자동으로 플러시가 발생하며(FlushModeType.AUTO, 기본값), 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송합니다. 직접 호출하는 경우에는 em.flush()를 이용할 수 있습니다. 플러시 자체는 영속성 컨텍스트를 비우지 않고 변경내용을 데이터베이스에 동기화합니다.
참고로 JPA는 기본적으로 데이터를 맞추거나 동시성 관련된 것을 데이터베이스 트랜잭션에 위임합니다.
자바 ORM 표준 JPA 프로그래밍 - 기본편
Object Persistence with JPA
[JPA] 준영속 상태와 변경 감지
데이터베이스 스키마 자동생성
JPA는 데이터베이스를 자동으로 생성해주도록 ddl-auto 옵션을 설정할 수 있습니다. 옵션의 종류는 create, create-drop, update, none, validate 종류가 있습니다. 주로 개발환경이나 테스트 서버에서는 update를 사용해야 하고 실서버에서는 절대 사용하면 안됩니다. 주로 운영서버에서는 validate나 none을 사용합니다. validate는 엔티티와 테이블이 정상 매핑되었는지만 확인합니다. none이라는 개념은 실제 없고, 주석처리하는 것과 동일한 효과를 갖습니다.
jpa:
hibernate:
ddl-auto: create
DDL 생성기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행로직에는 영향을 주지 않습니다. 즉 validation 용도로 사용하기에 좋습니다.
엔티티 매핑
@Entity, @Table
@Entity
@Table(name="TABLE", schema="NAME",
uniqueConstraints={@UniqueConstraint(name="unique_pid", columnNames="PersonalId")})
public class Table {
// Entity 속성 생략
}
@Column
@Column(name="location", length=20, nullable=false)
unique 제약여부도 걸 수 있지만, unique 제약의 이름을 설정하기 어렵기 때문에 @Table 위에 코드처럼 직접 설정해주는 것을 권장합니다.
name을 설정할 때는 별도 지정이 없이도 스프링부트에서는 자바의 Carmel Case 이름을 Snake Case로 변경해서 자동 매핑할 수 있는데, 직접 코드로 설정도 가능합니다. spring.jpa.hibernate.naming.physical-strategy 속성을 org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl 클래스로 설정하고, spring.jpa.hibernate.naming.physical-strategy 속성을 오버라이드하여 스네이크 케이스로 변환하는 클래스를 작성해야 합니다.
# 직접 구현시 -> 오버라이드
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
# 자동 구현시 설정
spring.jpa.properties.hibernate.physical_naming_strategy=com.example.SnakeCaseNamingStrategy
@Enumerated
@Enumerated(value = EnumType.STRING)
기본값인 EnumType.ORDINAL을 사용하면 enum 순서를 저장합니다.
@Temporal
날짜 타입을 매핑할 때 사용되며, TemporalType은 date, time, timestamp로 나뉩니다. Date, Calendar 매핑에 사용하며, LocalDateTime, LocatlDate의 경우에는 생략이 가능합니다.
@Transient
특정 필드를 컬럼에 매핑하지 않을 경우로 메모리 상에 어떤 값을 임시로 저장하고 싶은 경우에 사용됩니다.
@Lob
Large Object의 줄임말로 스프링이 추론하여 어떤 타입으로 저장할지를 판단할 때 사용하며, 문자는 BLOB으로 나머지는 CLOB 타입과 매핑합니다.
@Id
기본키를 직접 매핑하는 경우에 사용됩니다.
@GeneratedValue
기본키를 자동으로 생성해주는 어노테이션으로 GenerationType 전략은 4가지가 있습니다.
IDENTITY- 기본키 생성을 데이터베이스에 위임하는 전략입니다.
em.persist()시점에 즉시 insert하고 db 식별자를 조회해옵니다. - MySQL은
AUTO_INCREMENT값을 저장하고 나서 기본키를 구할 수 있을 때 사용됩니다. - 이 전략에서는 트랜잭션을 지원하는 쓰기 지연이 동작하지 않습니다.
- 기본키 생성을 데이터베이스에 위임하는 전략입니다.
SEQUENCE@SequenceGenerator시퀀스를 이용해서 기본키를 생성하는데, 시퀀스를 지원하는 데이터베이스에서 사용이 가능합니다.
TABLE- 키 생성용 테이블을 사용하는 경우입니다.
AUTO- 방언에 따라 자동지정되며, 기본값입니다.
GenerationType 전략을 사용할 때는 주의가 필요합니다. Hibernate 버전별 전략에 따라 기본키 자동 생성이 설정 값과 다르게 적용될 수 있다는 문제를 실제 겪은 적이 있는데 잘 정리된 블로그 글이 있어서 추가합니다.
[JPA] 기본 키(Primary Key)매핑
Spring Boot Data JPA 2.0 에서 id Auto_increment 문제 해결
🚴🏽 JPAQueryFactory 설정 이슈
Spring boot 3.x, Querydsl 5.0.0, Java 17
이슈사항
Spring Boot 3.x 버전에서는 javax가 아닌 jakarta persistence dependency를 사용해야 합니다. 그래서 build.gradle을 변경하고 EntityManager import를 변경 후에 JPAQueryFactory에 등록했음에도 제대로 작동하지 않는 모습을 보게 되었습니다.
여전히 JPAQueryFactory는 javax entity만을 요구하는 이슈가 발생했습니다.

왜 jakarta를 사용해야 하는지에 대하여
오라클 재단에서 이클립스로 JavaEE 기술 이전과 함께 기존에 사용하던 javax.* 대신 다른 명칭인 jakarta.*를 사용하는 JakartaEE가 반영된 Spring boot가 릴리즈되었기 때문입니다.
해결방법
먼저 Querydsl 사용을 위한 설정 부분을 보면, 변경된 jakarta로 되어 있습니다. 그리고 implementaion에도 jakarta를 명시해두었습니다. 이 부분은 문제가 없고 빌드나 Q class 생성에도 이상이 없었습니다.
에러를 살펴보면 EntityManager 인식문제가 제일 컸기 때문에 JPAQueryFactory가 왜 인텔리제이에서 의존성 주입이 제대로 되지 않았는지 알아봤습니다.
// querydsl
implementation "com.querydsl:querydsl-jpa:${queryDslVersion}:jakarta"
annotationProcessor "com.querydsl:querydsl-apt:${queryDslVersion}:jakarta"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"
위의 코드와 같이 classifier로 버전 뒤에 :jakarta 설정을 해주지 않아 생긴 문제였습니다. 이전 코드에 classifier를 추가해주었지만, 인식을 제대로 하지 못했습니다. gradle 빌드, clean, import 재작성, cache 삭제 등 방법을 사용했지만 해결되지 않았습니다.
결국 build.gradle 파일을 삭제하고 다시 생성하는 것으로 해결했습니다.
인텔리제이 문의에서도 알 수 있듯이 꾸준히 같은 이슈가 발생하고 있다는 것을 알게 되었습니다. 이전 dependency가 프로젝트 내에 어떤 source에 영향을 미치고 있기 때문인 걸로 추측됩니다.
Facing issue with dependency ,as when removed/updated a dependency it still persisted with older version . Even Settings>Maven> Always update snapshots did not work here. Had to delete .idea and .iml files and reimport the project. Quite a lot of time and effort went into getting a workaround for this. This is a very basic use case where developers need to keep updating the maven dependencies. Having to spend time and money on ultimate edition seems wasteful at the moment.
이렇다 할 뚜렷한 대안은 없지만 IntelliJ를 뛰어넘는 툴도 없기에 여러 가능성을 두고 살펴보는 것이 제일 좋은 방법인 것 같습니다.
결과
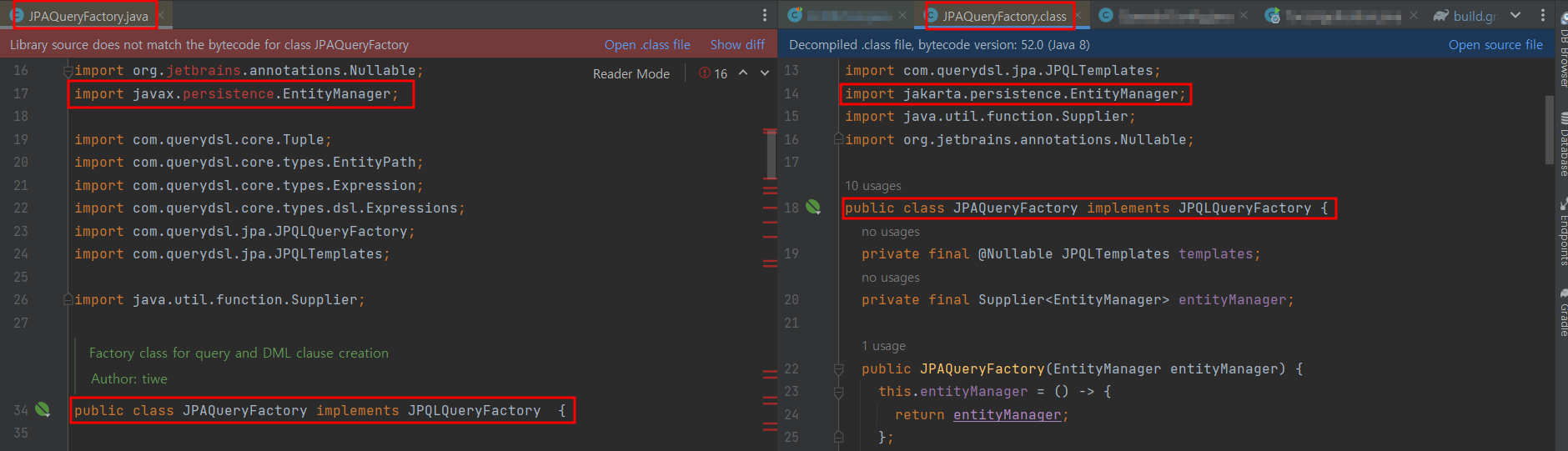
jakarta.persistence.EntityManager로도 JPAQueryFactory 빈 주입 및 생성에 문제가 없음을 확인했습니다. InitDB test도 통과했습니다!
정상적인 작동을 확인한 뒤에 코드를 살펴보면 java 파일은 javax를 여전히 요구하고 있지만 class 파일 생성시에 jakarta 타입의 EntityManager로 받는 것을 알 수 있습니다.
스프링 부트 3.0 으로 전환
spring boot 3.0
Intellij keeps old dependencies