Database
- 📖 데이터 중심 애플리케이션 설계
- 🚴 Query Tuning
- 🚴 DeadLock과 Redis 대기열
- Redis 기초
- 데이터베이스 종류와 MySQL
- 메시지 브로커 vs 이벤트 브로커
- H2 Database URLs
🚴 Query Tuning
Contents
쿼리 튜닝에 대해서
쿼리 튜닝은 데이터베이스 성능 최적화를 위해 질의문을 데이터베이스 옵티마이저가 더 나은 실행계획을 세울 수 있도록 하는 것을 말합니다.
쿼리 튜닝을 왜 해야 하는지 굳이 알아야 하는가에 대한 이야기를 하는 백엔드 개발자들도 봤지만, 개인적인 생각으로는 서버와 데이터베이스를 다루는 입장에서 당연히 알아야 하는 부분이라고 생각합니다.
그리고 쿼리 튜닝을 알면 자연스럽게 쿼리 그 자체에 대해서도 알고 native query, ORM에 대해서도 더 쉽게 이해할 수 있기 때문입니다.
1. Query Processing
Postgresql에서는 parser stage가 있는데 여기서 parser로 쿼리를 parse tree로 만들고 transformation 과정으로 parse tree 의미를 분석해 query tree를 만듭니다. (문서를 기준으로 작성했고 이 부분을 analyzer로 표기한 자료들도 있습니다.) 그리고 rewriter는 정해진 규칙 시스템에 따라 쿼리 트리를 다시 작성합니다. planner는 쿼리 트리를 바탕으로 실행될 plan tree를 만듭니다. 이 부분이 우리가 흔히 말하는 옵티마이저에 해당하는 부분입니다. 마지막으로는 excutor로 plan tree 생성 순서대로 쿼리를 실행합니다.
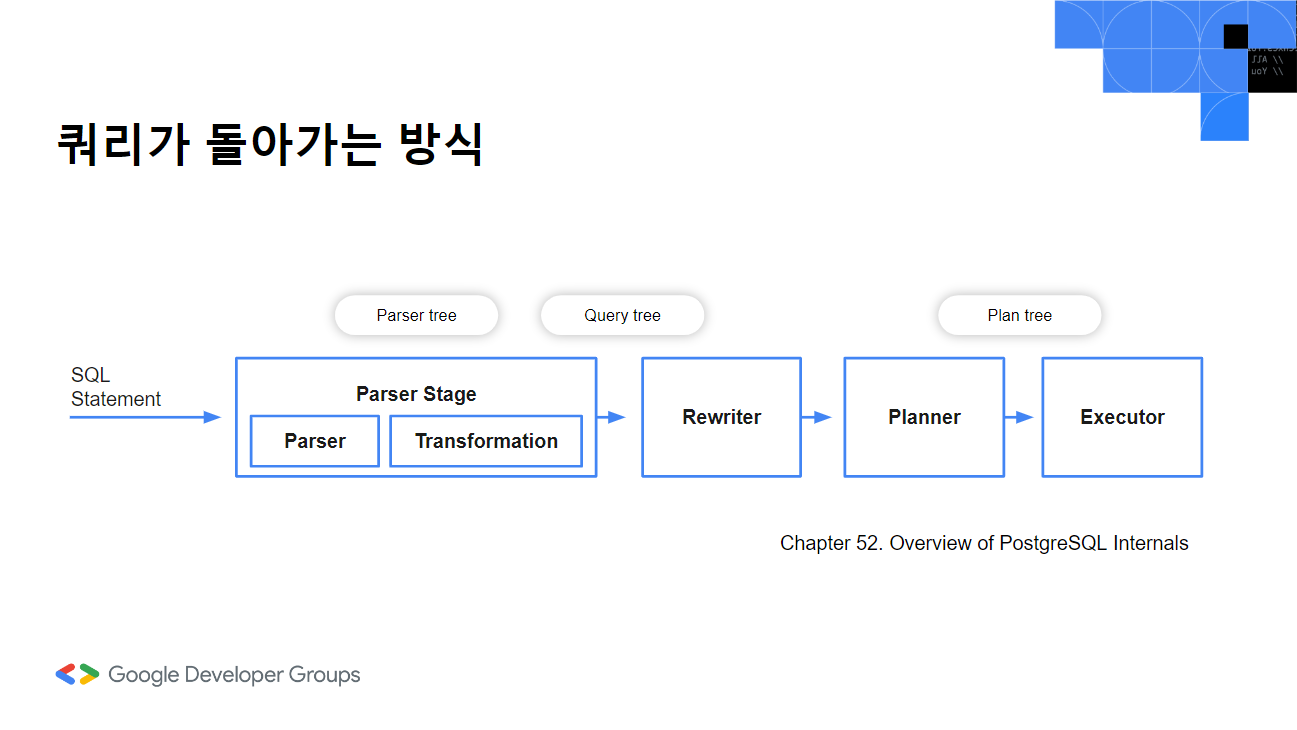
Parser
먼저 쿼리를 바탕으로 parser에서는 구문 분석을 진행합니다. sql 문법에 맞는지 확인하는 단계입니다. 쿼리의 내용 자체에는 관심이 없어요.
Transformation
이렇게 트리가 만들어진 후에 transformation 과정을 통해 query tree가 만들어집니다. 이전에는 구문 분석만 했다면 이번에는 실제 쿼리에 있는 테이블, 컬럼이 실제로 있는 유효한 내용인지를 확인할 수 있는지 여부를 확인하는 과정을 거치게 됩니다. 트랜잭션 과정에서 시스템 카탈로그를 확인하기 위해 두 부분이 parser와 나눠져 있는데, 여기서 시스템 카탈로그는 데이터베이스의 메타 데이터를 담은 장소라고 할 수 있습니다.
Rewriter
rewriter 단계에서는 query tree를 바탕으로 rule system을 구현하는 단계입니다.
Planner
planner 단계는 rewriter 단계에서 받은 query tree를 가지고 데이터를 찾아 실행계획을 위한 plan tree를 만듭니다. 실행계획에 따른 비용을 계산해서 효율적인 방식을 사용합니다. 공식문서에 따르면 다수의 조인으로 인한 과도한 시간과 메모리가 소요되기 때문에 일정 수의 join을 넘어가는 경우 Genetic Query Optimizer를 사용한다고 합니다.
Exector
exector 단계에서는 plan tree 의 노드를 순차적으로 수행해서 데이터를 가공합니다. explain analysis 처리한 쿼리 결과를 보면 다음과 같은 자료를 얻을 수 있습니다. WindowAgg(윈도우 어그리게잇)으로 비용, 반환한 행의 수, 시간 등을 나타냅니다. Planning time은 PostgreSQL이 실행 계획을 수립하는 데 걸린 시간입니다. Execution time은 쿼리를 실행하는데 걸린 시간을 의미합니다.
2. Query Execution Plan
쿼리 플랜은 다음과 같이 EXPLAIN을 사용해서 얻을 수 있습니다.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
SELECT
zip,
ROW_NUMBER() OVER (ORDER BY price DESC) AS price_rank,
RANK() OVER (PARTITION BY type ORDER BY price DESC) AS type_price_rank
FROM
test
WHERE
city = 'SACRAMENTO';
- analyze 실제 실행 계획을 분석하고 실행 속도 등 정보
- costs 쿼리 실행에 소요되는 비용
- verbose 실행계획에 더 자세한 정보, 어떤 인덱스, 어떤 테이블 스캔
- buffers 버퍼정보, 각 단계별 버퍼
- format json 실행계획을 json 반환하기 위해

이렇게 시각화된 자료로 얻을 수 있습니다. 그림으로 실행계획 순으로 그림으로 볼 수 있고 아래 테이블에서는 실행 계획을 의미합니다.
- exclusive 특정 단계에서 소요된 시간
- inclusive 해당 단계 + 하위 계획 단계를 포함한 총 시간
- rowx 는 각 단계에서 예상되는 행의 수
- actual은 실제 단계에서 반환된 행의 수
- plan은 실행 계획 단계의 실행 계획 방법과 관련된 정보
앞서 보여드린 쿼리 플랜을 다시 보겠습니다. WindowAgg(윈도우 어그리게잇)으로 비용, 반환한 행의 수, 시간 등을 나타냅니다. 첫 번째 괄호 부분은 예상 계획에 따른 것으로 옵티마이저가 예상하는 실행 계획의 시작 비용과 종료 비용을 표기한 cost, rows 예상 행의 수, width 결과 집합의 폭, 각 행의 폭이 116바이트라는 것을 의미합니다. 그 다음 괄호는 실제 실행시간과 실제 처리된 행의 수, 루프 수를 나타냅니다. planning time은 PostgreSQL이 실행 계획을 수립하는 데 걸린 시간입니다. execution time은 쿼리를 실행하는데 걸린 시간을 의미합니다.
쿼리 실행계획을 읽을 때에는 안쪽에서 바깥쪽으로 그리고 같은 들여쓰기로 표시된 경우는 위에서 아래 방향으로 읽습니다.
3. Query Tuning Approaches
쿼리 튜닝에 대한 발표를 하기 전에 정말 다양한 자료를 찾아봤는데 데이터베이스별, 난이도별 다양한 접근법과 이야기들이 있어 애초에 모든 내용은 담을 수 없겠다는 생각이 들었습니다. 그래서 가장 핵심적인 부분 몇 가지만 소개하는 걸로 발표주제를 잡았고 다양한 연령의 사람들이 많이 참여하는 행사인만큼 지루하지 않을 수 있는 정도의 내용을 담았습니다. 발표자료를 다 담기는 어렵고 핵심정리 내용을 4가지로 담아서 이 부분만 정리해보려고 합니다.
Where 조건절의 순서와 Like로 찾는 범위를 줄이자.
데이터가 많은 경우에 where 조건절의 순서로 인해 성능차이가 나는 경우가 있었습니다. like 조건에 % 와일드 카드를 양쪽에 두어 찾는 경우가 있는데 이럴 때는 인덱스 사용도 할 수 없고, 전체 테이블 조회로 시간이 소모됩니다. 하지만 앞에 문자열을 두게 되면 시작부가 고정되어 있어 인덱스 활용이 가능해집니다.
인덱스 유형을 알고 필요한 컬럼에 인덱스를 설정하자.
인덱스를 만들기 전에 진짜 그게 최선인가 고민해볼 필요가 있습니다. 불필요한 인덱스로 오히려 다른 쿼리 성능을 떨어트리는 방식이 될 수도 있기 때문입니다.
그럼에도 인덱스가 필요한 경우에는 자주 조회되고 쓰기가 자주 일어나지 않는 컬럼, 값 중복이 적은 컬럼, 연산 기능에 사용될 가능성이 높은 컬럼에 인덱스를 거는 것이 좋습니다. 추가하는 경우는 반드시 history를 사용해서 인덱스 사용시에 다른 쿼리와의 연관성도 살필 필요가 있습니다.
Postgresql에서는 지정없이 만들게 되면 기본적으로 b-tree 인덱스로 만들어집니다. BETWEEN, >, <, >=, <=와 같은 연산자를 사용하는 쿼리에 적합한 인덱스로 정렬된 순서로 데이터를 저장하기 때문에 ORDER BY 쿼리나 GROUP BY 쿼리에서도 유리합니다.
그 외에는 Hash 인덱스, GiST(Generalized Search Tree) 인덱스, GIN(Generalized Inverted Index) 인덱스, BRIN(Block Range Index) 인덱스 등이 있습니다.
결과 데이터 양에 따라 스캔 방식별 효율성이 달라진다.
스캔은 데이터를 조회해올 때 사용되는 방법으로 실행계획에서 가장 아래 노드에 있습니다. 가장 처음 시작된다고 할 수 있습니다.
Bitmap Index Scan, TID Scan 방식들이 있지만 여기서 헷갈릴 수 있는 인덱스 스캔 방식에 대해 설명하겠습니다.
Index Scan:
인덱스를 사용해 조건에 맞는 키를 찾고, 해당 키로 테이블 행에 접근합니다. 범위 검색이나 정렬된 데이터에 적합합니다. 실제 테이블 데이터에 접근해야 하므로 비교적 느릴 수 있습니다.
Index-Only Scan:
인덱스가 쿼리에 필요한 모든 데이터를 포함할 때 사용됩니다. 실제 테이블에 접근할 필요 없이 인덱스에서 데이터를 얻습니다. 매우 빠른 성능을 제공합니다.
Bitmap Index Scan:
여러 조건이나 인덱스를 사용하는 쿼리에 적합합니다. 조건에 맞는 행을 비트맵으로 표시한 후, 해당 행들을 테이블에서 검색합니다. 중간 규모 이상의 결과 집합에 효율적입니다.
결과값이 작다면 Nested Join이 되도록 인덱스 컬럼을 만들자!
Nested Loop Join (중첩 루프 조인)은 가장 간단하고 일반적인 조인 방법입니다. 외부 테이블(outer relation)을 순차적으로 스캔하면서, 각 행에 대해 내부 테이블(inner relation)을 매칭하는 행을 찾습니다. 외부 테이블이 작은 경우에 효율적이며, OLTP 워크로드에서 자주 사용됩니다. 그리고 내부 테이블의 조인 키에 인덱스가 있으면 중첩 루프 조인의 속도가 상당히 빨라질 수 있습니다.
🚴 DeadLock과 Redis 대기열
Contents
- Deadlock에 대하여
- Deadlock 어떻게 해결할 것인가
- Redis에 대하여
- Redis 대기열
- Redis 스핀락과 분산락
- Redis 스핀락과 분산락
- 성능테스트와 대용량 트래픽 해결을 위한 방안 고찰
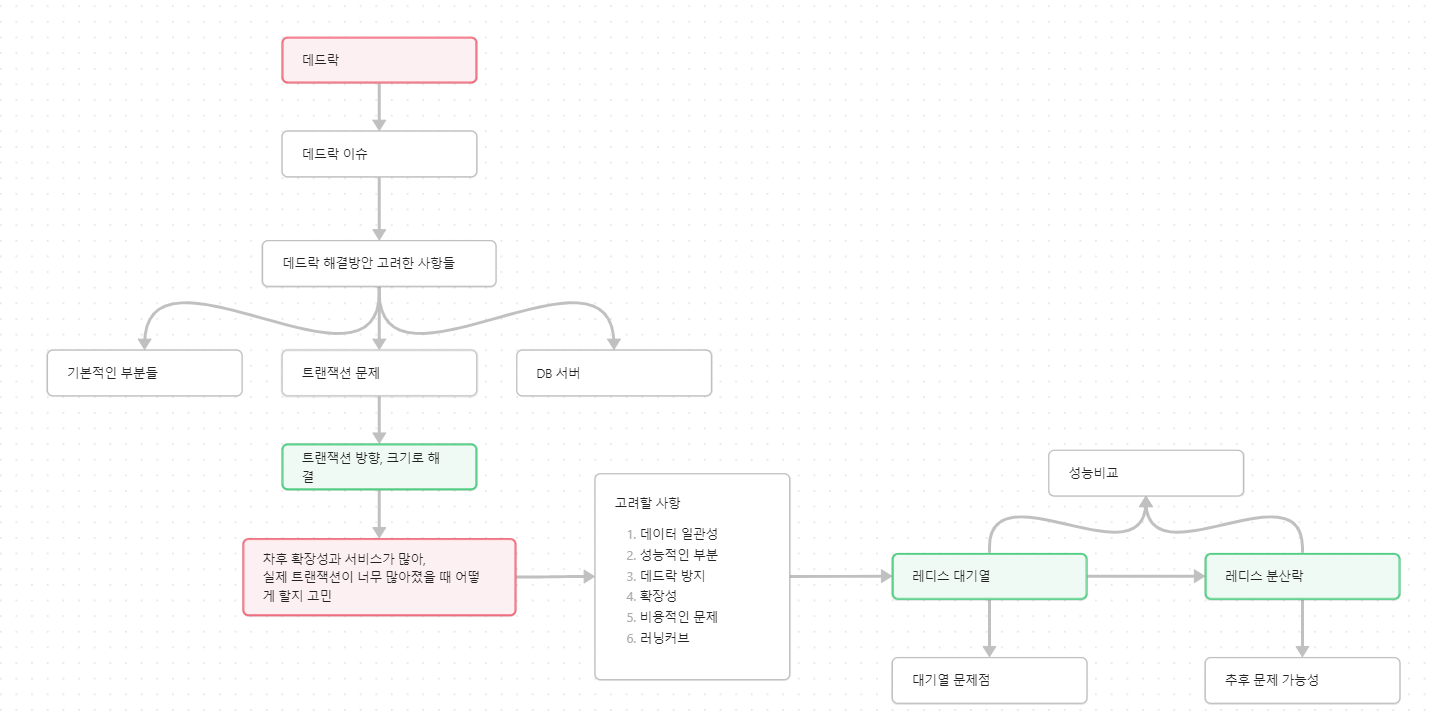
Flow Map
발표내용 설명에 앞서 이 포스팅은 발표 내용 중 일부만을 정리한 내용으로 포스팅만으로는 흐름 전달이 어려울 수 있다고 생각했습니다. 그래서 실제 발표를 준비하면서 만든 flow map 통해 어떻게 내용을 정리했는지 그리고 전반적인 순서들에 대해 먼저 이야기해보고자 합니다.
주 내용은 실제 경험한 deadlock 이슈 그리고 그걸 해결하기 위한 방법이 어떤 것들이 있는지에 대해 담았습니다. 이후에는 그 중에서 redis 대기열과 분산락을 이용해 순차 접근이 가능하도록 하는 과정을 설명했습니다.
핵심 해결과정 설명 전, 이해를 위해 redis에 대한 설명을 추가했습니다. 그리고 마지막으로 redis 대기열과 분산락 jmeter 성능비교 및 더 많은 트래픽을 견디기 위한 방법들에 대한 이야기를 담았습니다.
Deadlock에 대하여
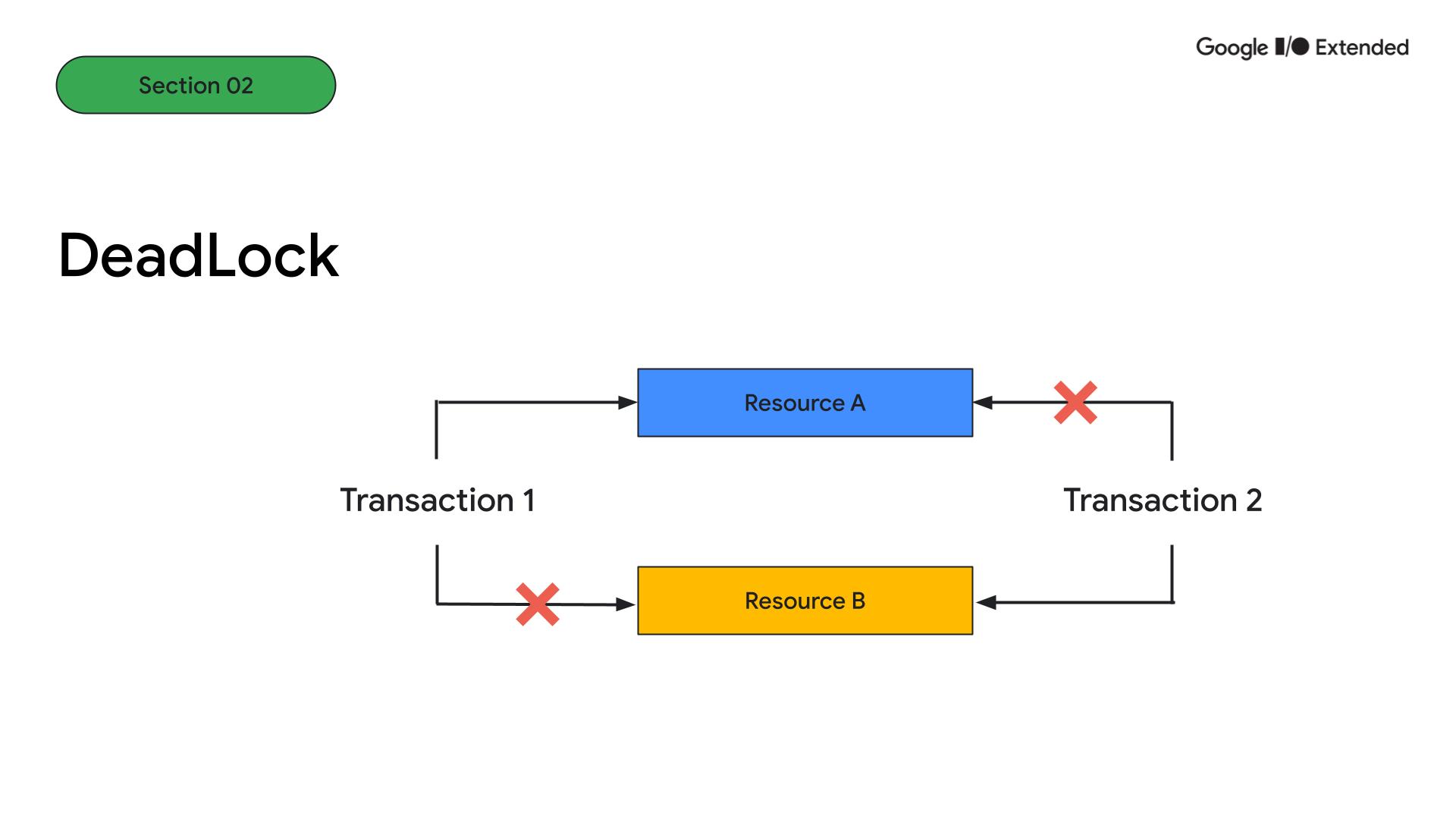
DeadLock은 두 트랜잭션이 서로 다른 리소스를 점유한 상태에서 상대 리소스 점유를 얻기 위해 기다리고 있는 교착상태입니다. Transaction 1이 Transaction 2가 점유한 리소스 B에 접근할 수 없고, 반대로 Transaction2도 리소스 A에 접근할 수 없는 상태가 되어 무한 대기가 발생하는 상황을 말합니다.
실제로 Deadlock이 발생했을 때 다음과 같은 에러가 났었습니다. 에러에서 보면 PID 61이 희생양으로 종료된 것을 볼 수 있습니다. 즉 제대로 반영되지 않고 종료되어 실제 예약이 등록되지 않은 상태로 종료되었습니다.
2023-02-06 11:57:33.526 WARN 3028 --- [o-8080-exec-431] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1205, SQLState: 40001
2023-02-06 11:57:33.526 ERROR 3028 --- [o-8080-exec-431] o.h.engine.jdbc.spi.SqlExceptionHelper : Transaction (Process ID 61) was deadlocked on lock | communication buffer resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
2023-02-06 11:57:33.527 ERROR 3028 --- [o-8080-exec-431] h.hsas.service.Exception Controller : ErrorResponse(location=[CannotAcquireLockException]
Deadlock 어떻게 해결할 것인가
당시에 어떻게 해결할지 많은 고민을 했고, 대기업에 근무하면서 큰 비용과 리소스를 자유롭게 운용할 수 있는 사항이 아니었기에 해결방안이 제한적이었습니다. 이 시점에서 제가 할 수 있는 조치들을 고민해보게 되었습니다. 실제로 큰 비용과 러닝커브를 들이지 않고 해결할 수 있는 방안들이기 때문에 기본적이지만 고려되어야 할 중요한 대안입니다.
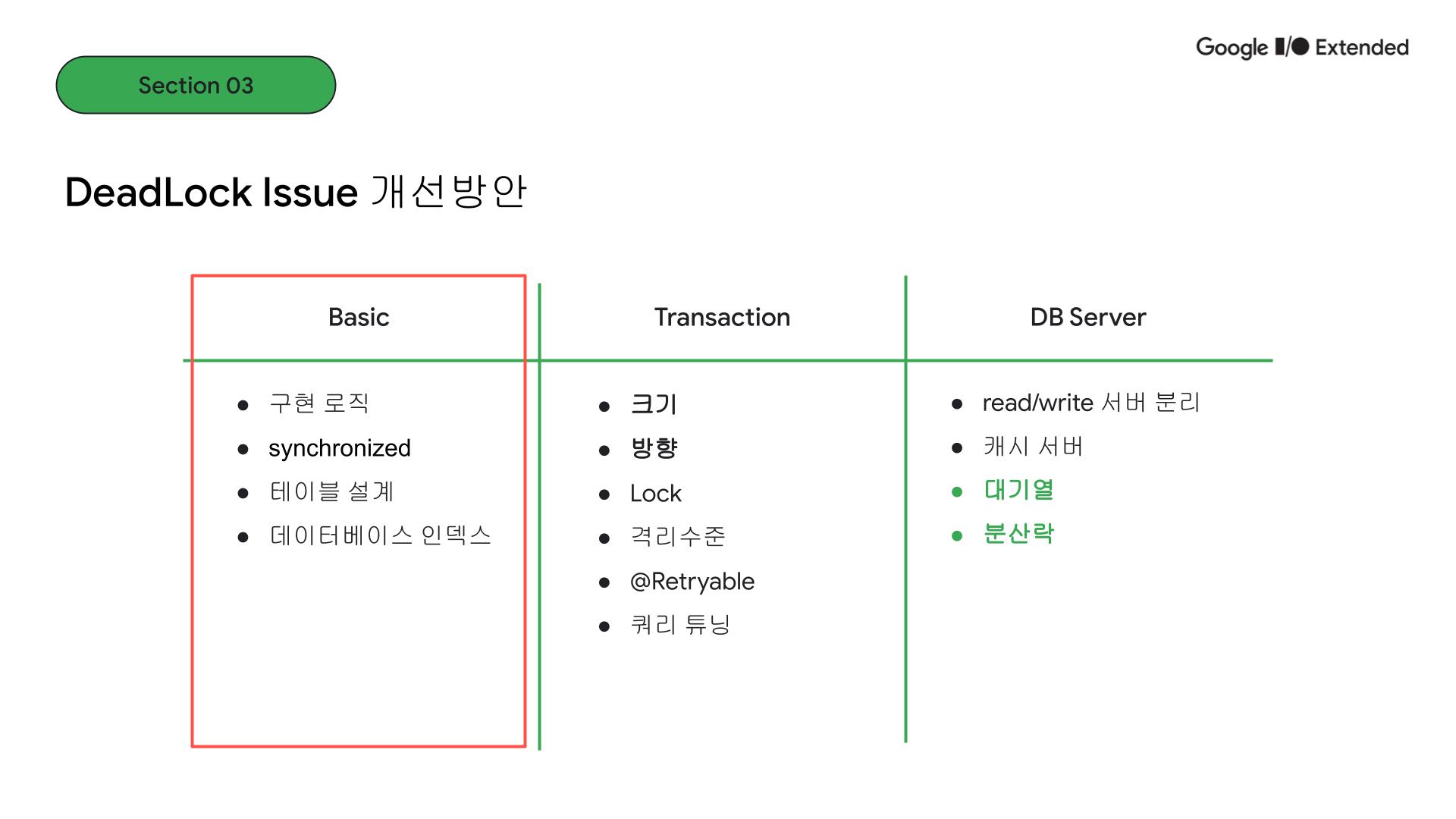
먼저 기본적인(Basic한) 부분에서 살펴보겠습니다.
코드의 구현 로직이나 테이블의 설계적 측면입니다.
예약 프로그램을 예시로 들면, 회원/관리자, 예약 신청, 후기, 등록, 기타 서비스와 같은 도메인들이 있을 수 있는데,
예약 신청이 가장 핵심 기능이고 트래픽이 몰릴 수 있다고 가정하면, 이 부분을 데이터베이스에서 읽어오거나 저장할 때 어떻게 구현되어 있는지
그리고 테이블 설계가 어떻게 되어 있는지 다시 살펴볼 필요가 있습니다.
그 다음 데이터베이스 인덱스 설정도 다시 확인해야 합니다.
Non-clustered index로 여러 컬럼들이 묶어서 하나의 인덱스 설정이 되어 있습니다. 이런 경우에는 단순히 Lock이 걸릴 때, 행 단위 row lock이 아닌 page lock이 걸릴 가능성이 높기 때문에 결국 deadlock 가능성도 높아집니다.
자바에서는 synchronized와 같이 동시성 제어를 위해 제공되는 기능이 있습니다. 다른 언어들로 따지면 뮤텍스, 락 기능입니다.
여러 요청이 있을 때 순차적으로 하나씩 메서드를 처리할 수 있도록 합니다. 하지만 이 synchronized로는 부족합니다. 단일 애플리케이션 환경에서는 문제 없지만, 분산 시스템 환경에서는 데이터 정합성을 보장받기는 어렵습니다.
트랜잭션 측면에서 고려할 사항은 어떤 것들이 있을까요?
먼저 위에 데드락 이슈를 해결하기 위해 적용했던 부분이 바로 이 트랜잭션 크기와 방향성을 일치시켜 주는 일이었습니다.
한 트랜잭션에 기능이 여러 개인 메서드가 들어가지 않도록 크기 단위를 조절할 필요가 있습니다. 트랜잭션 단위를 작게 만들어 락이 걸리는 시간이 작아지도록 할 수 있습니다.
그리고 여러 트랜잭션에서 데이터를 조회하는 메서드가 반대 순서로 진행된다면, 서로 다른 리소스를 점유하는 상황에서 데드락이 발생할 수 있습니다.
하지만 실질적으로 여러 서비스를 가진 복잡한 프로젝트에서 이렇게 간단하게 해결하기는 어려운 경우가 많습니다.
Lock이나 격리수준을 설정하는 방법도 있습니다. 간단하게 락은 여러 트랜잭션이 있을 때 동시에 접근하지 못하도록 제어하는 것이고 트랜잭션 격리수준은 어떤 트랜잭션의 변경 사항이 다른 트랜잭션에게 보이는지를 제어합니다.
Spirng JPA에서는 이렇게 락이나 격리수준을 설정하는 유용한 어노테이션을 제공하고, @Retryable을 사용해 재시도 설정도 가능합니다.
트랜잭션 단위의 쿼리가 어떻게 실제로 나가는지 확인해 볼 필요가 있습니다. 조인이 너무 많거나 조건이 너무 많다면 락의 범위가 커지면 데드락으로 이어질 수 있습니다.
트랜잭션 측면에서 고려할 사항은 어떤 것들이 있을까요?
실질적으로 앞에서 이야기한 부분은 코드를 작성하고 리펙토링 하는 과정에서 어느 정도 정리될 수 있지만 더 큰 트래픽과 확장성을 고려한다면, 시스템 설계적인 부분에서 고민해볼 필요가 있습니다.
read/write 서버의 분리입니다. 대부분의 애플리케이션은 읽기 비중이 높기 때문에 이렇게 마스터 서버를 두고 하위 replica 서버들로 읽기 요청을 처리하도록 할 수 있습니다. 이렇게 하게 되면 트래픽이 몰렸을 때 데이터베이스에 가중되는 부하를 분산시킬 수 있습니다.
성능이 빠른 인 메모리 데이터를 사용해서 캐싱 처리하는 방법도 있습니다. 캐시서버를 두는 방식으로 redis 캐싱 전략에서 look aside라는 방식을 보면, 먼저 캐시 서버에 데이터가 있는지 확인하고 캐시미스가 발생하면 디스크에서 조회 후 캐시 서버에 업데이트하고 반환하는 방식을 이용합니다. 즉, 이렇게 매번 디스크에서 데이터를 조회하지 않기 때문에 성능상에 이점이 있습니다.
마지막으로 대기열과 분산락입니다. 대기열은 리스트나 큐에 작업단위를 넣어 순차적으로 진행될 수 있도록 하는 방식입니다. 분산락은 분산시스템에서 동시성 제어를 위해 그림과 같이 락을 획득한 경우에 데이터나 자원에 접근할 수 있도록 하는 방식입니다.
Redis에 대하여
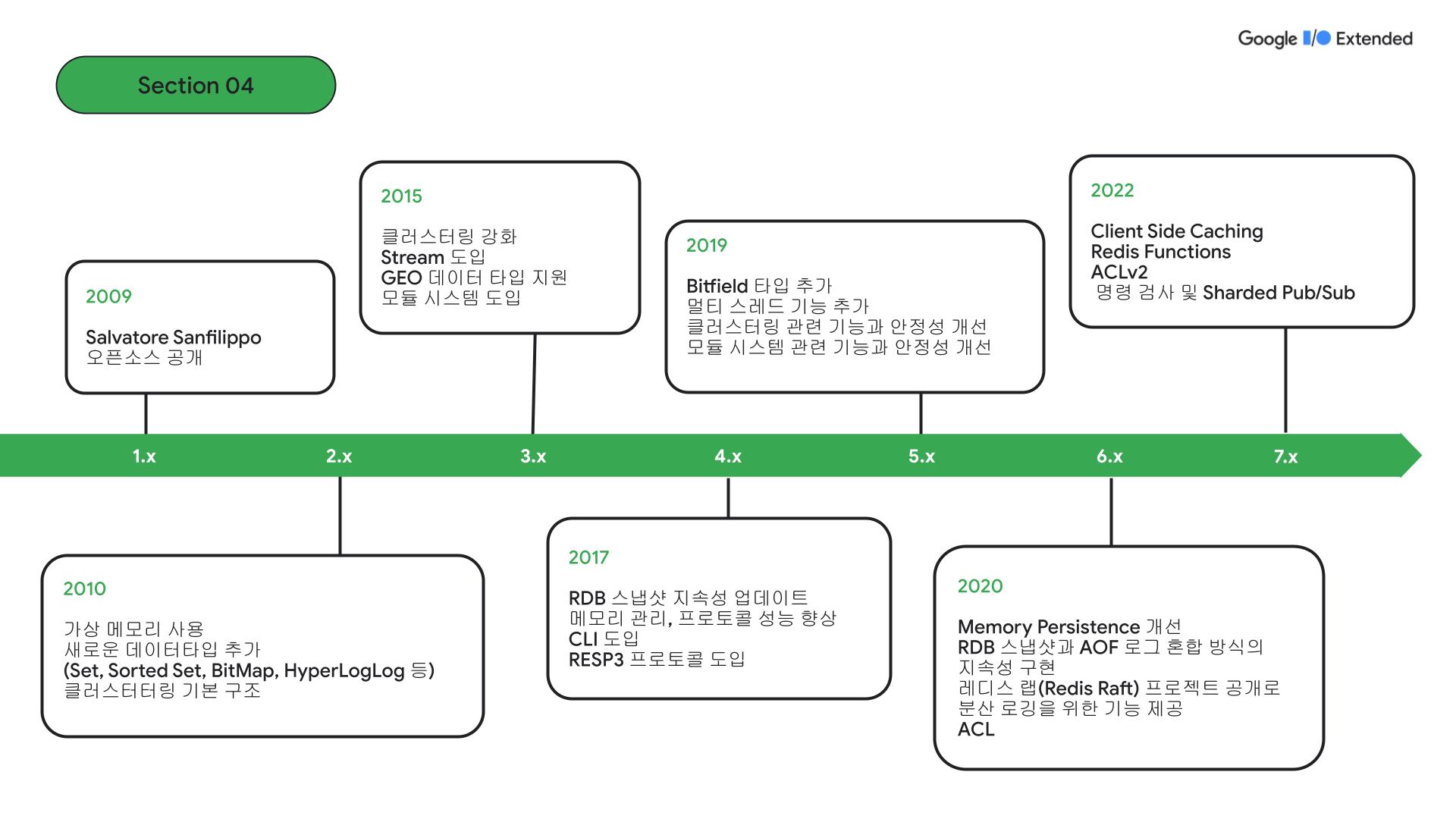
Redis Github new features를 보고 버전별로 정리한 자료입니다. 버전 7.0을 기준으로 뉴 스펙 중 가장 주목할 만한 기능은 Redis 함수, ACLv2, 명령어 내부 조사(command introspection), Sharded Pub/Sub이 있습니다.
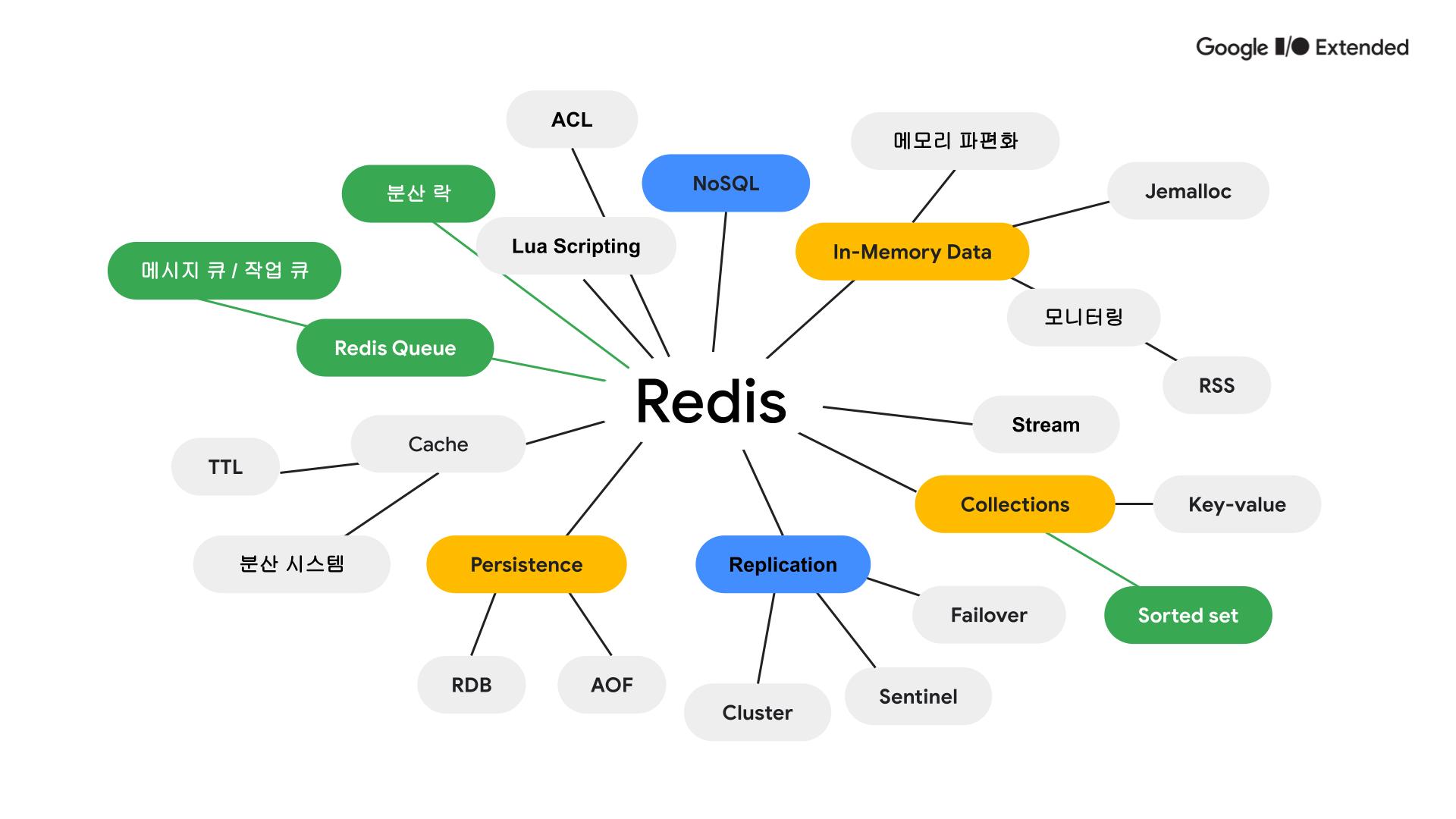
레디스는 NoSQL, In-memory 데이터베이스입니다. 그렇기 때문에 메모리 관리를 위한 모니터링을 하는 것이 중요합니다. Jmalloc으로 메모리 할당이 되며, 같은 크기의 자료를 저장하는 것이 메모리 파편화를 줄이는데 도움이 됩니다.
Redis는 Sorted set, set, hyperloglogs와 같은 다양한 자료구조를 지원합니다.
인메모리 데이터베이스이기 때문에 휘발성이 있습니다. 따라서 레디스는 이를 보완하기 위해 복제기능을 제공하는데 클러스터, 센티널과 같은 구조로 사용할 수 있습니다. 그리고 장애가 발생한 노드를 감지하고 마스터 노드로 승격시키는 failover 기능이 있습니다.
데이터 지속성을 위해 백업 스냅샷을 제공하는 RDB, 레디스 명령어를 로그 파일로 저장하는 AOF 기능이 있습니다. 둘 다 디스크 공간을 필요로 하기 때문에 적절히 조절할 필요가 있습니다.
레디스는 대표적인 캐시 서버로 분산 시스템에 사용될 수 있고, 데이터 신선도와 자원 절약을 위해 TTL 설정을 효율적으로 할 필요가 있습니다.
대기열과 분산락을 만드는데 사용되기도 하고 루아 스크립트를 사용합니다. 여러 개별 Redis 명령어를 네트워크를 통해 전송하는 대신, 루아 스크립트 하나로 여러 명령어를 한 번에 실행할 수 있습니다. 이는 네트워크 오버헤드를 줄이고 성능을 향상시킬 수 있습니다.
Redis 대기열
redis에서는 sorted set을 어떻게 관리할까요?
configuration 파일에 보면, entry가 128개 미만이고 모든 entry의 총합이 64byte 미만인 경우에는 ziplist 구조로 저장됩니다. 두 조건에서 하나만 벗어나도 skiplist 구조로 저장됩니다.
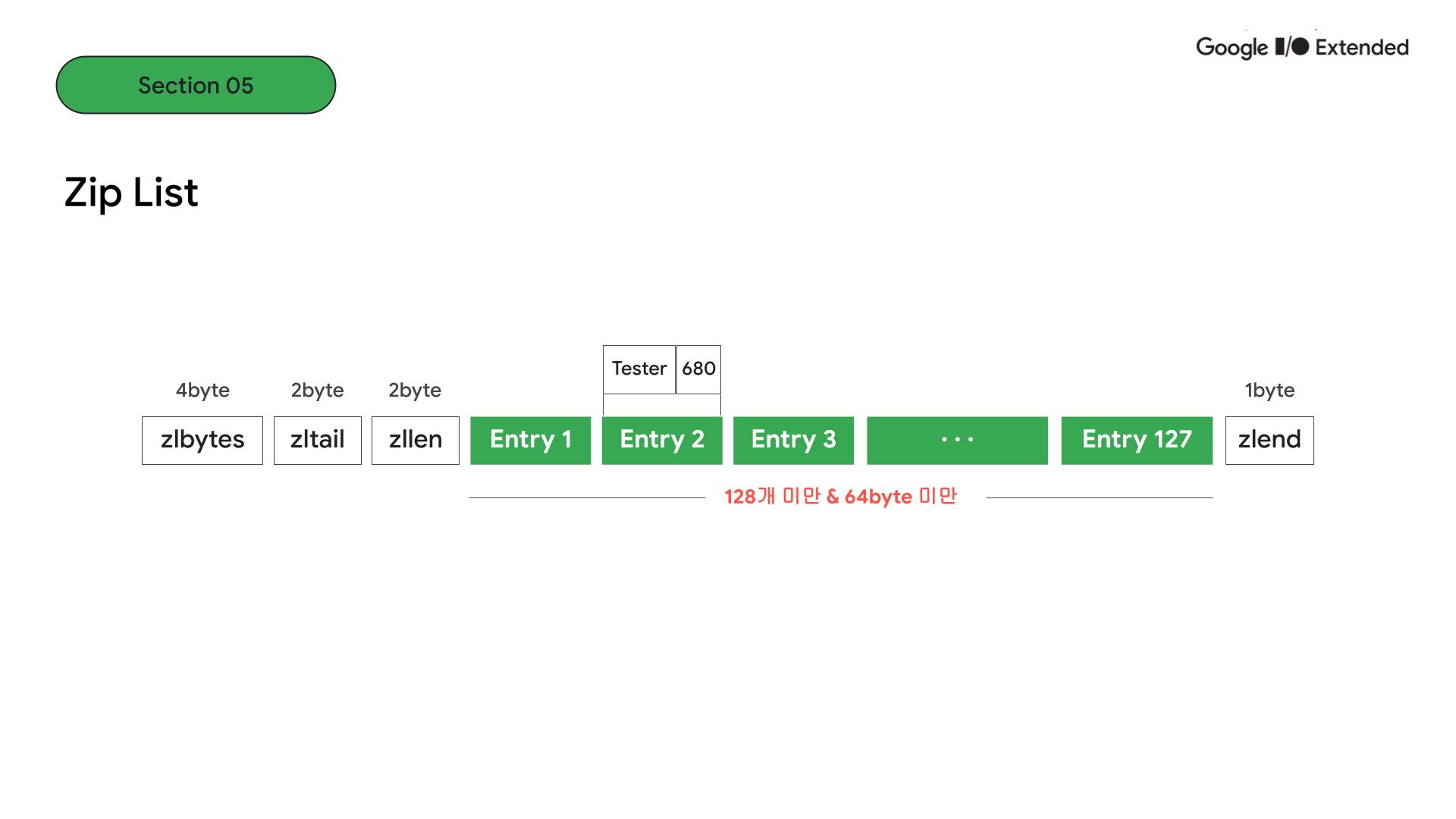
먼저 ziplist 구조를 보면, 상대적으로 entry가 작기 때문에 선형의 구조로 entry가 저장되는 것을 볼 수 있습니다. 한 entry는 값과 점수 쌍을 의미합니다.
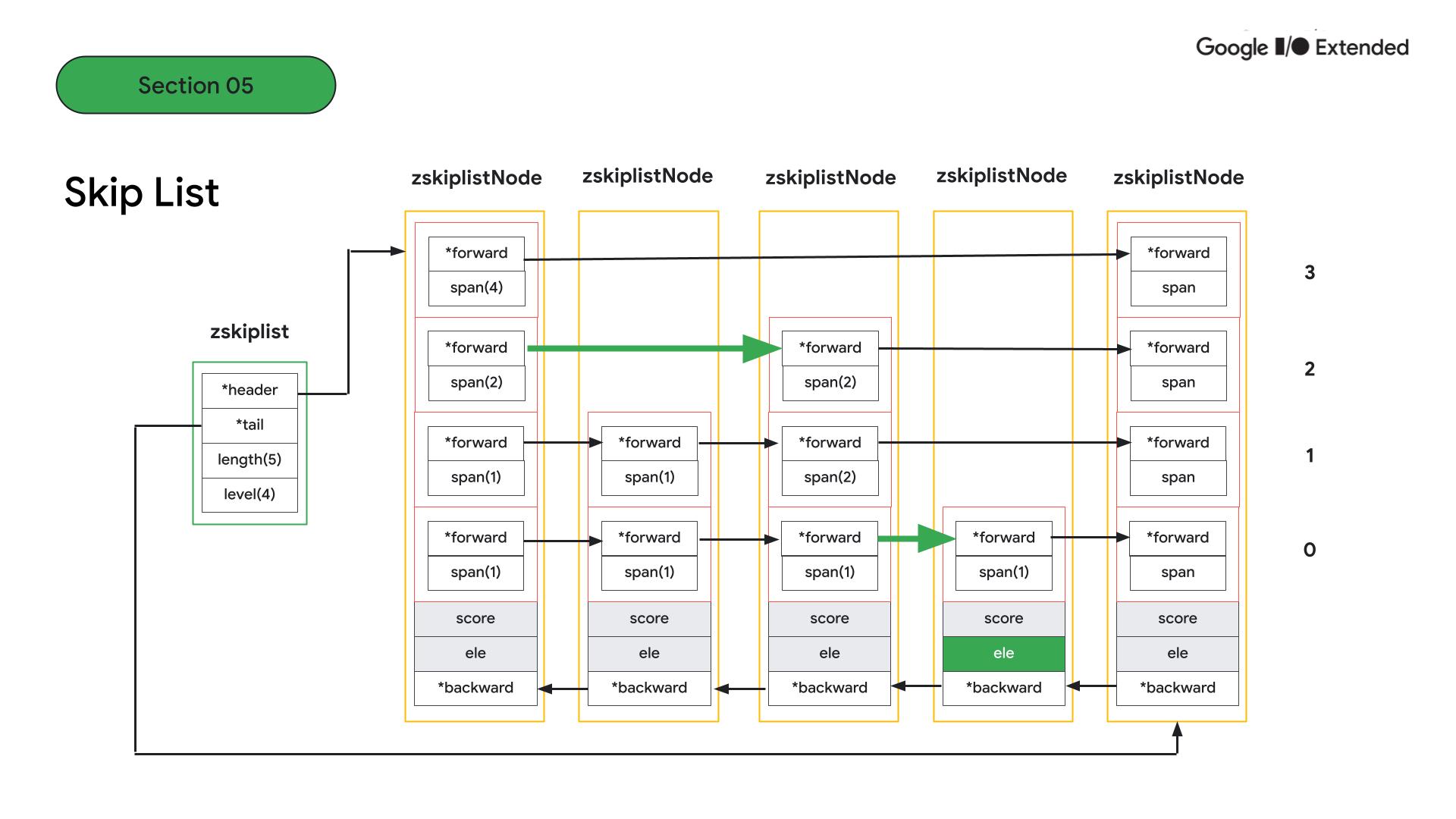
skiplist는 안에는 노드의 처음과 끝을 가리키는 header와 tail이 있고 노드의 갯수와 노드 내 level 수를 알 수 있습니다. 각 노드는 값과 점수 그리고 노드 내 레벨 안에 forward로 다음 노드를 알 수 있습니다.
예를 들어 네 번째 노드의 값 element를 찾는다고 하면, 높은 레벨에서 큰 단위로 점프한 다음, 다음 노드를 찾기 때문에 더 빠르게 검색이 가능합니다.
결과적으로 ziplist와 skiplist를 비교하면 시간복잡도 측면에서는 skiplist가 log n으로 좋지만, entry가 작거나 적고 메모리 관리가 중요한 상황에서는 ziplist를 사용하는 것이 좋습니다.
Redis 스핀락과 분산락
스핀락
스핀락은 계속 락을 얻기 위해서 계속 루프를 돌며 시도하는 락으로 부하가 커지기 때문에 루프에서 sleep 기능으로 텀을 주는 것이 좋습니다. 그리고 lock 점유시간도 작은 멀티 스레드 환경에서 사용하는 것이 좋습니다.
Spring에서는 의존성 추가로 redis 클라이언트 라이브러리 중 하나인 lettuce를 편하게 사용할 수 있습니다. Lettuce로 spin락을 구현하면 락을 획득하는 과정에서 일정시간을 두고 반복하는 기능을 제공하지 않기 때문에 락 획득 가능여부를 루프를 돌면서 체크하는 부분을 구현해야 합니다.
public boolean acquireLettuceSpinLock(String lockKey, long timeout, long startTime) throws InterruptedException {
boolean locked = redisTemplate.opsForValue().setIfAbsent(lockKey, "locked", timeout, TimeUnit.MILLISECONDS);
while (!locked && System.currentTimeMillis() - startTime < timeout) {
Thread.sleep(50);
}
if (!locked && System.currentTimeMillis() - startTime >= timeout) {
return false;
}
return locked;
}
public void releaseLock(String lockKey) {
redisTemplate.delete(lockKey);
}
반면 redisson 스핀락에서는 getSpinLock으로 RLock 객체를 얻을 수 있고, tryLock으로 반복 구문을 별도로 구현하지 않고 timeout과 단위 설정만으로 스핀락을 구현할 수 있다는 차이가 있습니다.
redisson.getSpinLock(lockKey).tryLock(timeout, timeUnit);
/**
* Returns Spin lock instance by name.
* <p>
* Implements a <b>non-fair</b> locking so doesn't guarantees an acquire order by threads.
* <p>
* Lock doesn't use a pub/sub mechanism
*
* @param name - name of object
* @return Lock object
*/
RLock getSpinLock(String name);
분산락
분산락은 분산 환경에서 여러 사용자 또는 스레드가 공유 데이터나 리소스에 접근할 때, 락을 획득해야 데이터베이스에 접근이 가능하게 합니다.
비관적 락은 단일 서버나 프로세스 내에서 데이터의 동시성을 제어하는데 사용되며, 분산 락은 여러 서버나 프로세스 사이에서 공유 리소스의 동시성을 제어하는데 사용된다는 차이가 있습니다.
redisson.getLock(lockKey).tryLock(timeout, timeUnit);
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
redission으로 분산락을 구현하게 되면 getLock() 메서드를 이용해 구현할 수 있습니다.
락 획득을 위해 단순히 lock() 메서드를 이용하지 않고 tryLock() 메서드를 사용하면 락 획득을 못했을 때 에러를 던지는 것이 아니라 재시도를 하게 되는데 실제 이 루아 스크립트를 redis excutor라는 클래스로 받아 redis에서 처리합니다.
성능테스트와 대용량 트래픽 해결을 위한 방안 고찰
Jmeter로 성능테스트를 진행했고 이벤트 목표 인원의 10배인 동시 접속자 수로 받는다고 했을 때, redis lettuce 스핀락, redisson 스핀락, redisson 분산락에서는 데이터가 100개로 limit에 맞게 들어온 것을 확인했습니다.
하지만 일반적인 비관적, 낙관적 락만으로는 동시성 제어가 부족함을 알 수 있었습니다.
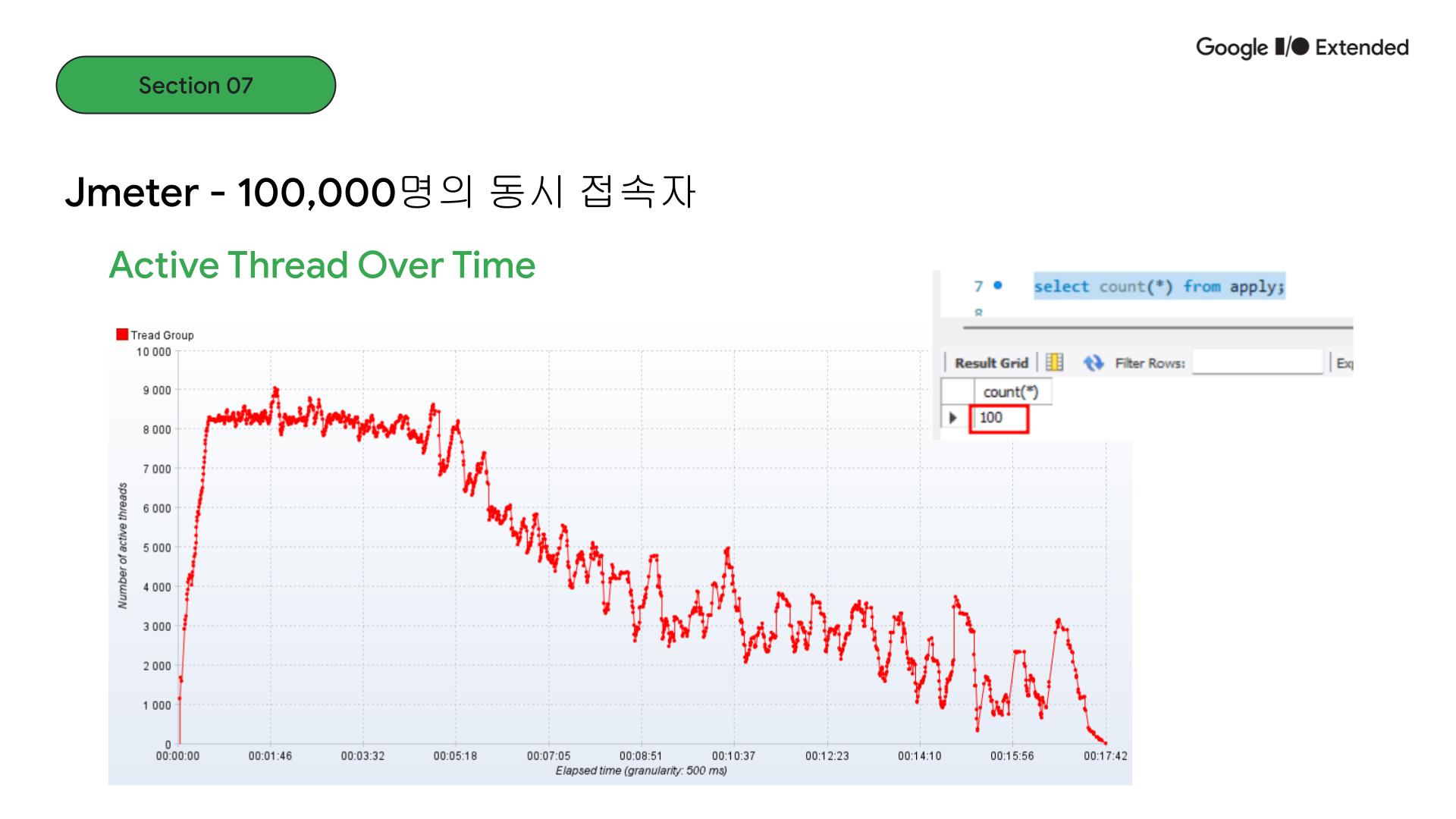
동시접속자 수가 10만일 때, 스레드 병목현상이 발생하는 것을 볼 수 있습니다. 그래도 데이터는 100개만 들어오는 것으로 정합성은 지켜지는 것을 확인할 수 있었습니다. 하지만 트래픽이 높아지니 분산락에도 이슈가 발생했습니다. Redis 서버 연결 확인을 위해 ping을 했을 때 pong 응답이 와야하는데 서버가 제대로 작동을 하지 못해 발생하는 문제였습니다. 단일 포인트인 Redis에 모든 트래픽이 쏠렸기 때문입니다.
org.apache.http.conn.HttpHostConnectException: Connect to localhost:8080 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused: connect at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:156) at org.apache.jmeter.protocol.http.sampler.HTTPHC4Impl$JMeterDefaultHttpClientConnectionOperator.connect(HTTPHC4Impl.java:409) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:376) at
org.redisson.client.RedisTimeoutException: Command execution timeout for command: (PING), params: [], Redis client: [addr=redis://localhost:6379]
at org.redisson.client.RedisConnection.lambda$async$0(RedisConnection.java:244) ~[redisson-3.18.0.jar:3.18.0]
at io.netty.util.HashedWheelTimer$HashedWheelTimeout.run(HashedWheelTimer.java:715) ~[netty-common-4.1.94.Final.jar:4.1.94.Final]
at io.netty.util.concurrent.ImmediateExecutor.execute(ImmediateExecutor.java:34) ~[netty-common-4.1.94.Final.jar:4.1.94.Final]
그럼 분산락의 한계는 어떻게 해결해야 할까요?
단일 장애지점이 된 redis 구조를 클러스터나 센티날로 변경해서 처리할 수 있습니다. 메모리 모니터링, 로그 레벨 등을 통해 미리 확인하고 주의해야할 이슈를 알림으로 받아보는 등의 관리가 필요합니다. 분산락을 얻기 위해 대기하는 시간을 줄이는 timeout 설정을 고려할 수도 있을 것입니다. 서비스 크기나 비용 지원이 가능하다면 이벤트 브로커를 활용하는 것도 대안이 될 수 있습니다.
Redis 기초
오픈 소스 기반의 인메모리 데이터 저장 및 캐싱 시스템으로, 메모리 내에서 데이터를 빠르게 저장하고 검색할 수 있는 데이터 구조 서버입니다. 주로 다양한 데이터 구조(문자열, 해시, 리스트, 셋, 정렬된 셋 등)를 지원하며, 주로 높은 처리량과 낮은 지연 시간을 필요로 하는 응용 프로그램에 사용됩니다. 또한 Redis는 영속성을 제공하여 메모리에 저장된 데이터를 디스크에 지속적으로 저장할 수 있습니다.
Cache Register / Cache / Main Memory(DRAM) - In-Memory database / Storage(SSD, MDD)
Redis Collections
String, List, Sets, Sorted Sets, Hash
Redis Replication
- Secondary에 replicaof 또는 slaveof 명령어 전달
- Primary에 sync 명령
- Primary는 fork헤서 disk에 해당 정보를 전달하고 fork 이후 데이터를 계속 secondary에 전달
Redis Cache를 사용하기 적합한 경우의 예
- 인증 token 저장
- Ranking Board 이용
- 유저 API Limit
- 자료(list) 잡 큐
사용시 주의사항
1. key 값이 int의 최대값을 넘는 경우, 장애 발생 가능성 고려
2. 메모리 관리의 중요성
메모리 파편화가 일어나기 때문에 이론적으로 copy write가 발생하면 최대 2배 이상의 메모리 공간 확보가 필요할 수도 있습니다.
- 즉 Redis 캐싱 서버는 작은 인스턴스 여러 개로 두는 것이 좋습니다.
- 파편화 자체는 유사한 데이터 크기들이 있을 때, 메모리 파편화 가능성이 낮아집니다.
3. swap 지양하기
Physical 이상의 메모리를 사용하는 경우 위험하며 실제로 swap이 있어서 이상의 메모리를 사용해도 문제가 없는 것 같지만 swap을 사용한다면, 계속 디스크에 접근하기 때문에 효율이 좋지 않을 수 있습니다.
4. Replication-Fork
5. RSS 값을 모니터링
- Redis 메모리 자체는 작게 사용한다고 해도 실제 많은 key 삭제가 발생하거나 하는 이슈가 있을 수 있습니다.
6. Single Thread기 때문에 발생하는 문제점들
Pocket으로 하나의 Command가 완성되면 process Command에서 실행
7. 하나의 작업을 실행하기 때문에
O(N)의 다음 작업들은 피하기KEYS,FLUSHALL,FLUSHDB,DELETE COLLECTIONS,GET ALL COLLECTIONS
메시지 브로커 vs 이벤트 브로커
이벤트 브로커로 사용되는 프로그램들은 메시지 브로커로도 사용이 가능합니다.
메시지 브로커 (Message Broker)
Redis 큐
메시지 브로커는 송신자(프로듀서)와 수신자(컨슈머) 간의 비동기적인 데이터 흐름을 중개하는 시스템입니다. 메시지 브로커는 메시지를 보내는 쪽과 받는 쪽 사이에서 데이터를 버퍼링하고, 필요한 경우 메시지 큐, 토픽 등의 개념을 사용하여 데이터의 송수신을 관리합니다.
- 데이터를 큐에 넣고 큐에서 데이터를 처리하는 방식으로, 비동기적으로 작업을 처리하거나 데이터를 분산 처리하는 용도로 사용됩니다.
- 발행자(Publisher)가 이벤트를 특정 주제(topic)에 발행하고, 해당 주제를 구독하고 있는 구독자(Subscriber)가 이벤트를 수신하는 방식입니다.
- 서로 다른 애플리케이션 간에 데이터를 변환하거나 매핑하는 중개 역할을 할 수 있습니다.
이벤트 브로커 (Event Broker)
Apache Kafka, RabbitMQ, ActiveMQ, NATs, Amazon SQS
이벤트 브로커는 주로 이벤트 기반 아키텍처에서 사용되며, 이벤트의 발생, 전달, 처리를 관리하는 시스템입니다. 이벤트는 시스템 내에서 발생한 중요한 상황이나 변화를 나타내며, 이를 다른 컴포넌트나 애플리케이션에 효과적으로 전달하기 위해 이벤트 브로커를 사용합니다.
- 여러 시스템 또는 마이크로서비스 간에 발생한 이벤트를 통합하고 중앙에서 관리함으로써 데이터 일관성을 유지하거나 중복 이벤트를 제거합니다.
- 이벤트, 메시지 1개만 두고 개별 엑세스 관리
- 딱 한 번 일어난 데이터 저장, 단일 진실 공급원
- 장애 지점부터의 재처리
- 많은 양의 실시간 데이터 스트림 처리
- 이벤트, 메시지 1개만 두고 개별 엑세스 관리
- 특정 이벤트를 특정 컴포넌트나 서비스로 라우팅하여 처리할 수 있게 합니다.
- 이벤트 순서를 관리하거나 이벤트 처리를 지연시키는 등의 흐름 제어 기능을 제공합니다. **
- 카프카, 레빗엠큐, 레디스 큐의 큰 차이점! 이벤트 브로커와 메시지 브로커에 대해 알아봅시다.
H2 Database URLs
H2는 자바 기반 오픈소스 RDBMS입니다. 서버 모드와 임베디드 모드의 인메모리 DB 기능을 지원합니다.
실행방법
설치하고 나면 기본 경로로 설정했다면, C:\Program Files (x86)\H2\bin 위치에 실행파일 h2.bat이 생기고 H2를 실행해서 사용할 수 있습니다. (제 컴퓨터 OS는 현재 Window인 관계로 Window 기준으로 작성했습니다.)
실행 후에는 자동으로 브라우저로 H2 콘솔이 열리게 됩니다. localhost로 연결하고 이 때 JDBC URL 대로 실행하면, C:\사용자\{사용자명} 위치에 DB파일 test.mv.db이 생성되는 것을 볼 수 있습니다.
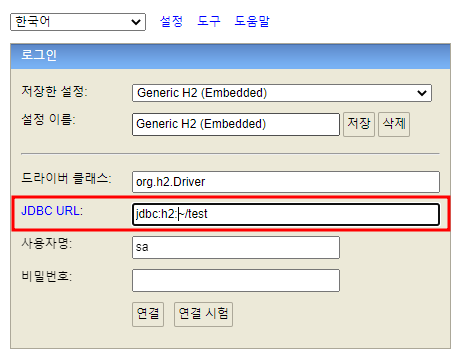
DB 파일이 생성된 후에는 파일모드가 아닌 tcp를 이용한 네트워크 모드인 jdbc:h2:tcp://localhost/~/test 경로로 들어가지는 것을 확인할 수 있습니다.
왜 tcp모드를 사용하고 JDBC URL의 종류는 어떤게 있을까요?
처음 H2를 사용할 때, 가장 헷갈렸던 부분이라서 다시 톺아보기로 했습니다. H2는 다양한 연결방식을 지원합니다. 처음 설치 후 jdbc:h2:[file:][<path>]<databaseName> 기본으로 되어 있던 모드가 Embedded(Local) Database로 사용하는 방식입니다. 이 때 해당 경로에 DB파일이 없는 경우에는 자동으로 생성되는데 이 때 권한이 있어야하며, 그 권한은 URL주소에 보면 jsessionid 키 값으로 권한이 부여됩니다.
DB 파일 생성 후에 사용했던 모드는 Remote 모드입니다. 이렇게 접근하는 이유는 직접 파일 접근을 막고, TCP 소켓을 사용한 접근으로 애플리케이션과 콘솔이 동시 접근했을 때의 오류를 방지하기 위함입니다. 이렇게 하면, 여러 명의 클라이언트가 같은 데이터베이스를 조회할 수 있습니다.
마지막은 In-Memory 방식입니다. DB 연결을 끊으면, 데이터가 사라지고 지속적이지 않기 때문에 test방식으로 추천되는 방식으로 private하게 사용하기 좋으며, jdbc:h2:mem:로 url을 작성합니다.
Database URL Overview
H2, DB 파일 저장 경로는?
H2 Database 설치, 서버 실행, 접속 방법 (Windows, MacOS)